
Mon Jul 14 / Alex Lyzhov, Preetam Joshi, Puneet Anand
Attain remarkably higher Agentic success rates with the powerful and fastest available instruction evaluation model.
As AI agents increasingly integrate into products and workflows, a critical challenge has emerged: while AI Agents excel at writing and reasoning, they often struggle to consistently follow instructions. Simple directives such as “do not include personal data” or “adhere to this date format” can easily be overlooked, leading to costly errors, particularly when dozens of AI agents are handling core tasks within customer support, healthcare, legal, and finance.
That’s why we developed the Instruction Following Evaluation (IFE) Model – a novel model designed to automatically extract each instruction from your Agent (LLM) prompts and verify how well your AI agents are following these instructions.
Both instruction extraction and instruction evaluation work in real-time (latency is as low as 200ms, depending on the GPU used). The model provides immediate feedback flagging unfollowed instructions and explaining the reasoning behind them. The model consistently outperforms other models like GPT-4o-mini in this instruction following evaluation task.
The Instruction Following Evaluation Model extracts key instructions from your application prompts and rigorously compares the AI’s output against those directives. It identifies subtle, easily missed errors that would typically require manual review, preventing issues such as revealing sensitive information, repeating facts unnecessarily, utilizing incorrect date formats, or any other specific prompt instructions. Here is a detailed explanation of how the model provides value:
Consider this example where we use Gemma 4B to answer questions about student loans:
Context:
Income-Driven Repayment (IDR) plans help lower federal student loan payments based on income and family size, with four options available: REPAYE, PAYE, IBR, and ICR. REPAYE and PAYE require payments of 10% of discretionary income, with forgiveness after 20 years for undergraduate loans and 25 years for graduate loans. IBR varies between 10% and 15% based on when loans were taken, with forgiveness after 20 or 25 years, while ICR calculates payments as the lesser of 20% of discretionary income or a fixed 12-year repayment amount, with forgiveness after 25 years. Eligibility requires a verified FSA ID, recent income documentation, and annual recertification of income and family size; failure to recertify may increase payments and interest. Joint filers must include their spouse’s income unless separated, and only Direct Loans qualify unless others are consolidated. Private loans are ineligible, and borrowers in default must make satisfactory arrangements before enrolling.
User Query:
All my loans are for graduate studies, at which date in the future are they forgiven?
Prompt:
Ensure that the response does not include any content hallucinated due to ambiguity. Use the European date format (DD/MM/YYYY).
Here is what the AI generates:
“If your loans were for graduate or professional study, they will be forgiven on 07/11/2045 which is 20 years from today (07/11/2025) with the REPAYE plan, and on 07/11/2050 which is 25 years with the PAYE, IBR, and ICR plans.”
Here is what the IFE Model catches:
Without the IFE Model, these subtle details in the output could have been easily missed. With IFE, the issue is flagged and can immediately be corrected.
IFE delivers tangible benefits:
IFE was developed using a proprietary dataset of diverse prompts, outputs, and meticulously crafted instruction sets, resulting in exceptional proficiency at understanding and enforcing instruction extraction and following. Here are its key technical highlights:
The model automatically extracts instructions from any given prompt, eliminating the need for manual annotation. This capability streamlines the evaluation process and ensures consistency across different applications.
The model outputs scores for all instructions in under 700 milliseconds, operating on one L40S GPU at 10 queries per second (QPS) with 8 instructions per query. Depending on the GPU used, latency can be as low as 200 milliseconds, making it suitable for real-time applications. The model supports up to 256K tokens context window.
With an accuracy of approximately 84%, the IFE Model outperforms the same class of models like OpenAI’s GPT-4o-mini model. This high level of precision ensures reliable evaluation of LLM outputs.
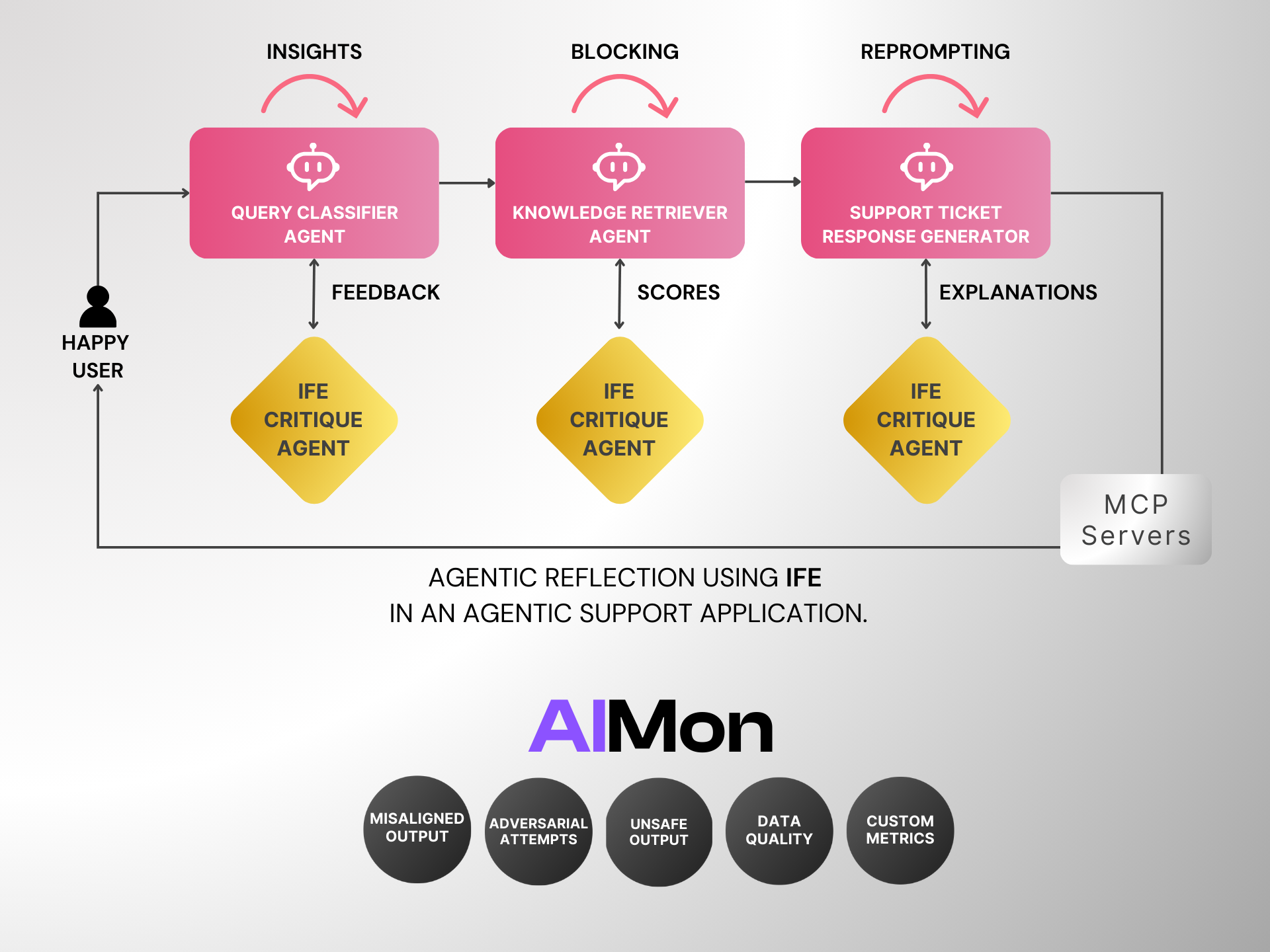
In agentic reflection scenarios, where AI agents assess and refine their actions, the model provides critical insights through Instruction Following Evaluation at each Agentic step. This support enhances the success rates of agentic workflows by ensuring that AI agents remain aligned with their objectives, increasing overall accuracy and reducing cost.
Not only Instruction Following, AIMon supports over 20 metrics out of the box that help “reflect” on each agent’s output while incurring only on the order of 200ms latency!
AIMon Internal Dataset: Our test set contains diverse prompts and system instructions across multiple domains, generated through a multi-stage process including data collection, conditional/unconditional instruction generation, model response generation using various models, and label/explanation generation via engineered reasoning models. This demonstrates the model’s capability beyond constrained IFEval-style instructions.
FollowComplexInstruction: We evaluated on this larger, more complex variation of IFEval (https://github.com/meowpass/FollowComplexInstruction) without training on similar prompts, testing generalization to unseen instruction patterns.
For instruction extraction, we evaluate span match accuracy and conditional label accuracy (given correct span identification). For instruction following evaluation, we measure the model’s ability to accurately assess compliance across both simple and complex instruction sets, comparing performance against baseline models like GPT-4o-mini.
AIMon IFE outperforms GPT-4o-mini in both instruction-evaluation and label prediction tasks while being significantly faster. On the FollowComplexInstruction benchmark, AIMon achieves higher accuracy (0.799 vs. 0.779) with drastically lower latency (~0.35s quantized vs. 5.58s). On AIMon’s internal test sets, it shows superior label accuracy (0.903 vs. 0.859) and F1 score (0.933 vs. 0.927), along with exceptional extraction performance (Span F1: 0.874 and Label F1: 0.954). This makes AIMon both more accurate and more efficient.
| Model | Balanced Accuracy | F1 | Latency (s) |
|---|---|---|---|
| GPT-4o-mini | 0.779 ± 0.024 | 0.756 ± 0.029 | 5.58 ± 0.17 |
| AIMon IFE | 0.799 ± 0.012 | 0.757 ± 0.016 | ≈ 0.35 (quantized) and 0.52 ± 0.01 (unquantized) on A100 |
| Model | Label Balanced Accuracy | Label F1 |
|---|---|---|
| GPT-4o-mini | 0.859 ± 0.014 | 0.927 ± 0.007 |
| AIMon IFE | 0.903 ± 0.011 | 0.933 ± 0.008 |
| Model | Span IoU | Span F1 | Label Balanced Accuracy | Label F1 |
|---|---|---|---|---|
| AIMon IFE | 0.822 ± 0.019 | 0.874 ± 0.020 | 0.870 ± 0.040 | 0.954 ± 0.011 |
Unlike off-the-shelf LLMs that are trained to cater to a variety of horizontal tasks, the IFE model was specifically trained to evaluate a model’s instruction-following capabilities across both simple prompts and complex instruction sets.
The model was trained in-house for multiple months for instruction extraction and instruction evaluation. This is why it consistently outperforms models like GPT-4o-mini (as shown in our results) when identifying instruction-following errors. It remains focused on a single objective: did the output adhere to the instructions?
IFE seamlessly integrates with most AI platforms and tools, including agentic systems, RAG pipelines, and custom evaluation systems thanks to AIMon’s API-based integration. It can handle multiple instructions simultaneously, processing them in under one second and providing real-time validation. See the documentation for more details.
The proprietary training and evaluation datasets that underpin the IFE Model — spanning diverse prompts, complex instruction sets, and multi-stage label generation — were built and curated using Dataframer.ai. Dataframer is a platform born directly out of this kind of work: the need to systematically produce, manage, and iterate on high-quality datasets for training specialized AI evaluation models. Without the dataset infrastructure that Dataframer provides, building a model of this precision and speed would not have been feasible.
As AI continues to gain momentum, tools like the IFE Model will become increasingly essential for ensuring reliable and trustworthy AI systems. It brings discipline to your AI workflows, while greatly increasing reliability of agents.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.