Agentic Reflection Part 3: A Smarter Loop for Smarter Models
What if your Large Language Model (LLM) could rewrite its own answers until it got things right … automatically?

The latest from our team on Enterprise Generative AI.
Agentic Reflection Part 3: A Smarter Loop for Smarter Models
What if your Large Language Model (LLM) could rewrite its own answers until it got things right … automatically?

The Un-leaderboard: Google, OpenAI, and Anthropic Self-Reported Hallucination and Accuracy Scores
This isn't a third party leaderboard. It's a snapshot of what OpenAI, Google, and Anthropic self report about their models. These factuality and hallucination metrics are often buried in system cards, so we surfaced them to shed light on a persistent issue: even the most advanced models still struggle with the truth.

Agentic Reflection Part 1: Continuous Agentic Monitoring, Reflection, and the Role of IFE
In this article, we’ll focus on the importance of continuous monitoring and reflection in building reliable AI agents. We will explain that even the most advanced language models often make critical errors when executing complex, multi-step instructions, which limits their reliability in production settings. We will introduce agentic monitoring (real-time verification of an agent’s behavior) and reflection (self-checking and revising outputs) as key mechanisms to catch and correct mistakes early to enable scalable, reliable agent deployment in high-stakes applications.
Agentic Reflection Part 2: Implementing the Reflection Pattern in Agentic AI Applications
Learn how reflective agents can validate model behavior and catch instruction violations without human oversight.
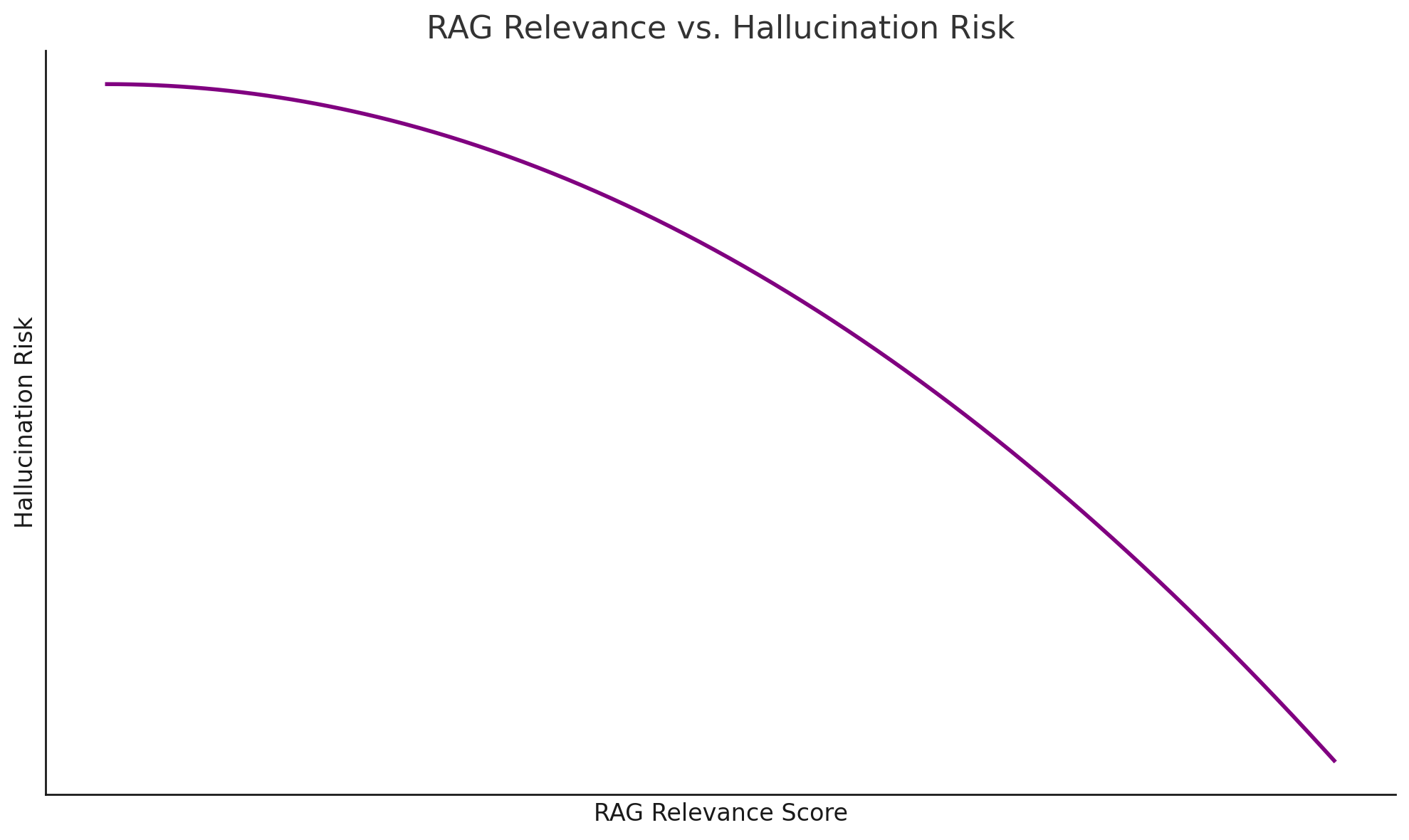
Boosting RAG Relevance by 150% and overall AI app quality by 40% with Milvus and AIMon
Inspired by a set of problems our direct customers faced, we decided to create a notebook that demonstrates how you can significantly optimize key metrics such as RAG Relevance, Instruction Adherence, and Hallucination rates.
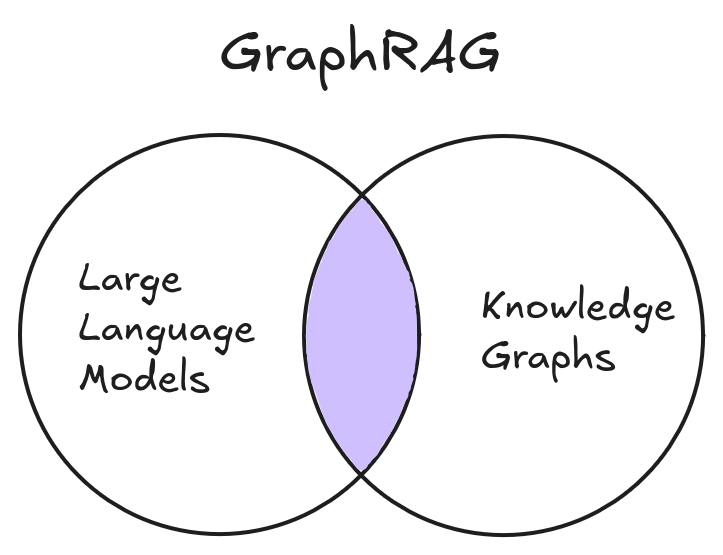
Enhancing LLM Applications with GraphRAG
GraphRAG combines structured knowledge graphs with traditional retrieval methods to improve context, reduce hallucinations, and enable complex reasoning in LLM applications.

DeepSeek-R1: Promising Innovation But With Accuracy Concerns
This blog examines the launch of DeepSeek-R1, a breakthrough yet imperfect AI model that challenges traditional high-cost AI systems. It covers its key innovations, market impact, and the potential limitations compared to industry leaders like GPT-4.

Revolutionizing LLM Evaluation Standards with SCORE Principles and Metrics
The SCORE (Simple, Consistent, Objective, Reliable, Efficient) framework revolutionizes LLM evaluation by addressing critical limitations in current evaluation systems, including LLM dependency, metric subjectivity, and computational costs. It introduces comprehensive quality, safety, and performance metrics that enable organizations to effectively assess their LLM applications while focusing on development rather than evaluation setup.

A Deep Dive into Agentic LLM Frameworks
I went to meet a few people around the SaaStr and Dreamforce Conferences in the San Francisco Bay area and found that agentic LLMs are a hot topic in the valley. Let's dive into how agentic LLM frameworks are marking an evolution in artificial intelligence.

Are LLMs the best way to judge LLMs?
”LLM as a judge” is a general technique where a language model, such as GPT-4, evaluates text generated by other models. This article dives into the pros and cons of using this popular technique for LLM evaluations.

How to Fix Hallucinations in RAG LLM Apps
AI hallucinations are real, and fixing them in RAG-based apps is crucial for keeping outputs accurate and useful.
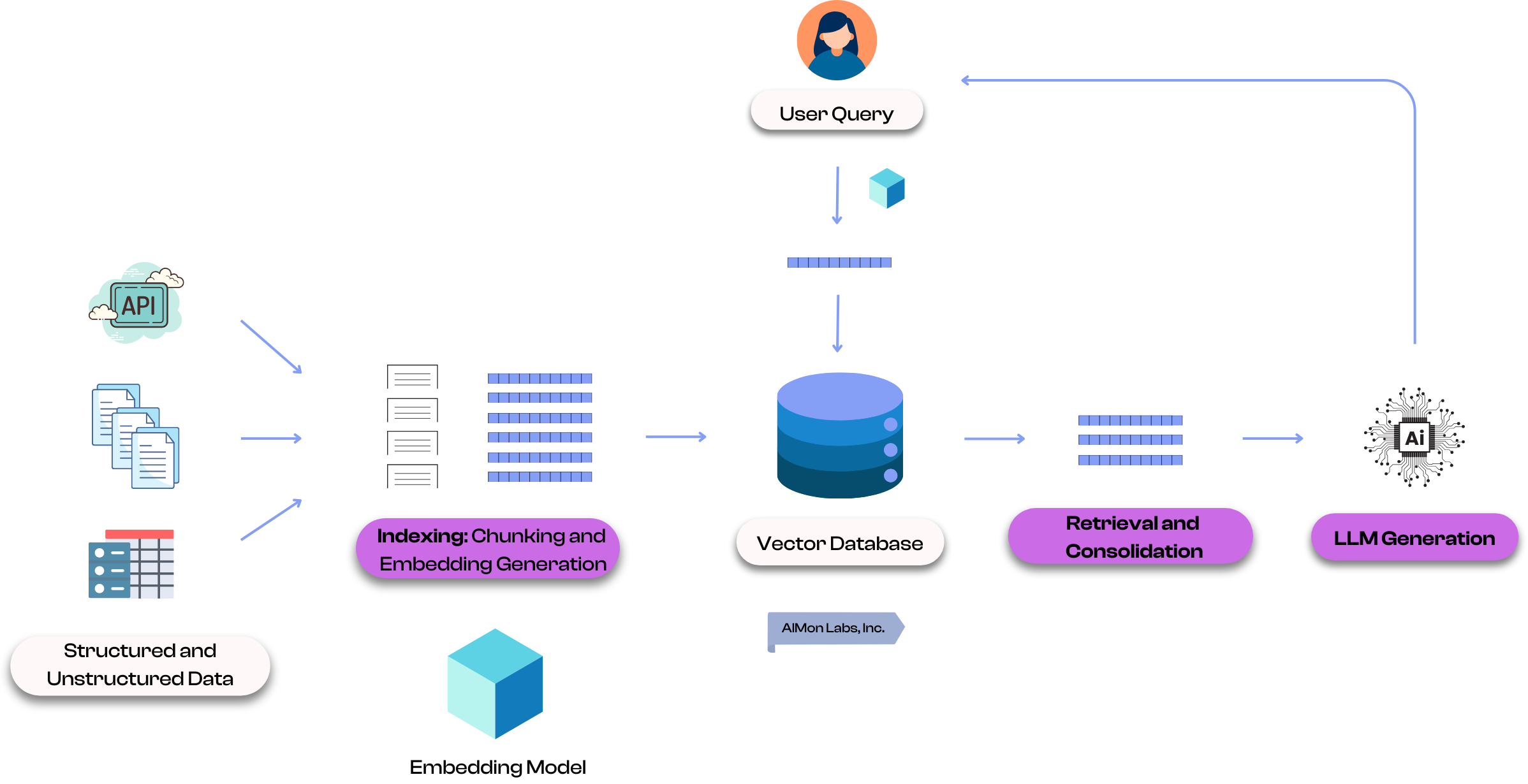
An overview of Retrieval-Augmented Generation (RAG) and it's different components
RAG is a technique that enhances the generation of an output from a Large Language Model (LLM) by supplementing the input to the LLM with relevant external information. In this article, we will cover the different components and types of RAG systems.

The Case for Continuous Monitoring of Generative AI Models
Read on to learn about why Generative AI requires a new continuous monitoring stack, what the market offers currently, and what we are building

A Quick Comparison of Vector Databases for RAG Systems
In this article, we’ll walk through four popular vector DBs — ApertureDB, Pinecone, Weaviate, and Milvus — and compare them based on their key features and use cases.
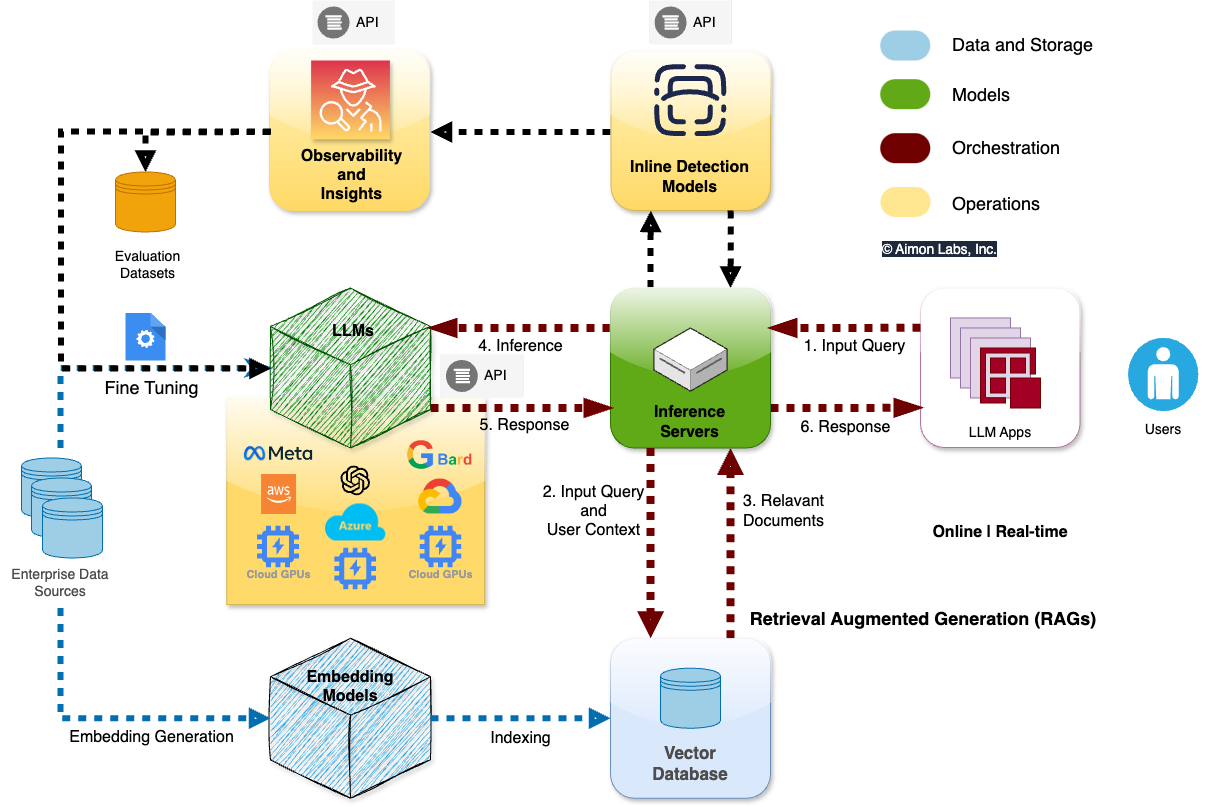
An Expert’s Guide to Picking Your LLM Tech Stack
Join us as we examine the key layers of an LLM tech stack and help identify the best tools for your needs.

Top Problems with RAG systems and ways to mitigate them
This short guide will help you understand the common problems with implementing efficient RAG systems and the best practices that can help you mitigate those problems

Top Strategies for Detecting LLM Hallucination
In this article, we’ll explore general strategies for detecting hallucinations in LLMs (in RAG-based and non-RAG apps).

Hallucination Fails: When AI Makes Up Its Mind and Businesses Pay the Price
Stories where AI inaccuracies negatively impacted the operational landscape of businesses.