
Thu Apr 03 / Preetam Joshi, Puneet Anand
Inspired by a set of problems our direct customers faced, we decided to create a notebook that demonstrates how you can significantly optimize key metrics such as RAG Relevance, Instruction Adherence, and Hallucination rates.
RAG (Retrieval-Augmented Generation) Relevance is critical for large language models (LLMs) and agentic applications because it directly impacts the accuracy, efficiency, and reliability of their outputs. In these systems, the quality of the retrieved context determines how well the model can ground its responses in factual, task-specific, or domain-relevant information.
High relevance ensures the model isn’t just generating plausible text but is actually reasoning over meaningful, context-rich data which is crucial for applications like customer support, research assistants, or autonomous agents making real-world decisions. Poor retrieval leads to hallucinations or irrelevant answers, while high RAG relevance enhances trust, accuracy, and user experience.
In today’s competitive landscape of AI applications, achieving meaningful performance improvements can be challenging. This guide will walk you through a proven approach to enhance your LLM (Large Language Model) applications with significant gains in both overall accuracy and retrieval quality.
Building effective LLM applications that reliably retrieve and process information remains difficult, especially when working with specialized content like meeting transcripts.
A systematic approach to evaluation and improvement can yield dramatic results!
Inspired by a set of problems our direct customers faced, we decided to create a notebook that demonstrates them and how AIMon’s models are utilized to significantly optimize key metrics such as RAG Relevance, Instruction Adherence, and Hallucination rates.

For this demonstration, we worked with the MeetingBank dataset which is a benchmark collection created from city councils of 6 major U.S. cities. While the full dataset contains 1,366 meetings with over 3,579 hours of video, transcripts, meeting minutes, agendas, and other metadata, we used a carefully curated subset of 258 transcript items totaling approximately 1 million tokens. We also developed challenging test queries specifically designed to stress-test retrieval systems and reveal performance limitations.
The smaller dataset can be found here.
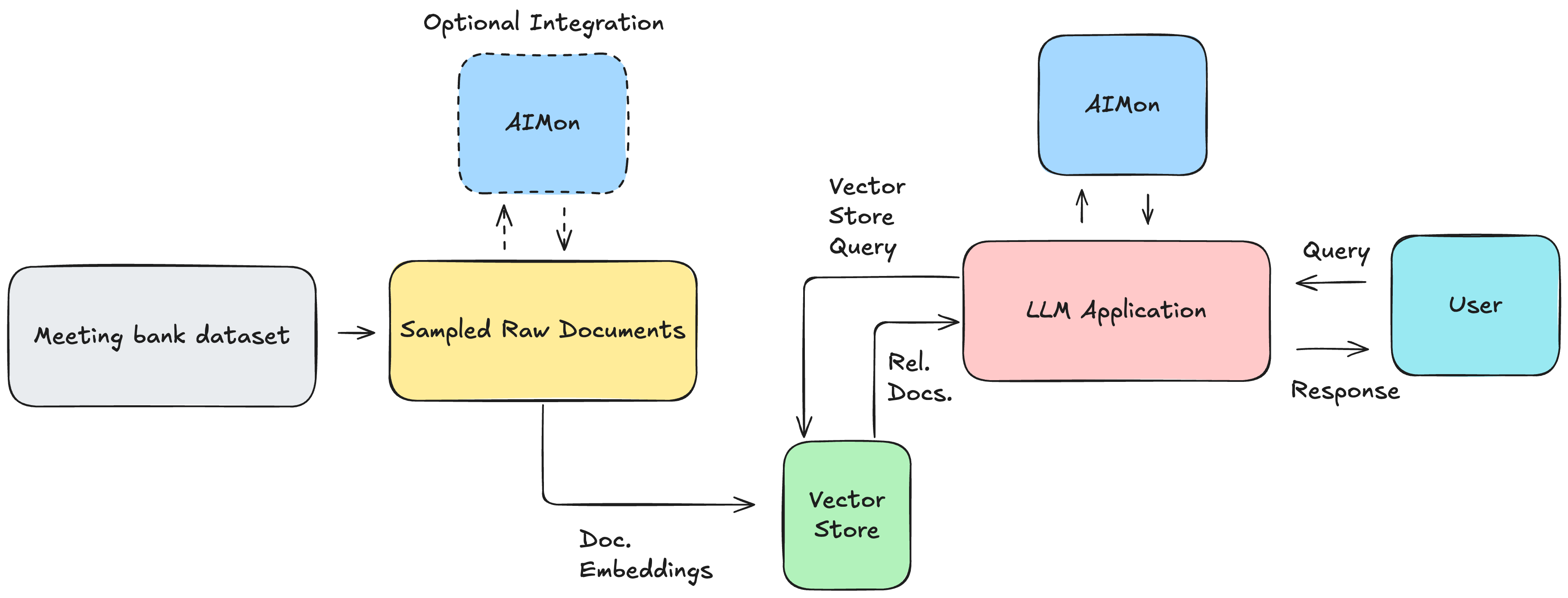
Then we used Milvus as our vector database, LlamaIndex for a simplified implementation, and AIMon for evaluating and tracking metrics at different key stages of building our optimizations.
Then, we took a sample of 12 queries to run this notebook with. This is not a complete quantitative study but a small qualitative dataset to demonstrate the problem-solutions without burning high $$$ on GPUs. Please feel free to copy the notebook and run it with an internal, larger dataset.

The key to improvements is precise measurements at various stages. Our overall quality metric combines three essential aspects:
Our starting point is to use a simple measure, the Levenshtein distance to match documents to the above set of queries and pass the top 3 matched documents to the LLM as context to be used for answering the queries. The following image shows the results at this stage. Here are the highlights of what we observe:
It takes ~168 seconds to process queries (very inefficient)
Achieves an overall quality score of ~51
Achieves retrieval relevance score of only ~14
After establishing our baseline metrics, it’s time to implement a proper vector database. This step is critical not just for quality improvement but also for reducing query latency as we just observed that the brute force approach is painfully slow at 168 seconds per query.
Our implementation focuses on two critical components:
Throughout this process, we leverage AIMon to continuously evaluate our system against the three key metrics we’ve established: hallucination detection, instruction adherence, and context relevance. This real-time feedback loop allows us to make targeted improvements rather than guessing what might work.
The initial vector database implementation gives us a modest but meaningful improvement as our quality score increases by about 33%. This validates our approach and gives us a more efficient platform to build upon. More importantly, it significantly reduces query latency, making our application much more responsive.
Adding Milvus as a vector database with pre-computed embeddings helps boost performance significantly:

Now for the most significant gains, we introduce AIMon’s innovative domain-adaptable RAG Evaluation + re-ranker combination model called RRE-1, which is seamlessly integrated with LlamaIndex as a postprocessor, to refine document retrieval. This method, as depicted in the figure, utilizes an advanced matching algorithm to elevate the most pertinent documents.
A key differentiator is the re-ranker’s customizability; by leveraging the task_definition field, users can tailor performance to specific domains, mirroring the adaptability of prompt engineering. This high-efficiency re-ranker operates with sub-second latency for approximately 2K-token contexts and boasts a top-tier ranking within the MTEB re-ranking benchmarks.
This approach reshuffles retrieved documents, ensuring the most relevant ones appear first, dramatically improving context quality for the LLM.
Here are the steps that we will follow in this step:
After implementing all three stages, the improvement trajectory shows remarkable gains:

By systematically applying these techniques, developers can achieve significant performance gains in their LLM applications, making them more accurate, relevant, and valuable to users.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.