
Wed Jul 31 / Puneet Anand, Preetam Joshi
In this article, we’ll focus on the importance of continuous monitoring and reflection in building reliable AI agents. We will explain that even the most advanced language models often make critical errors when executing complex, multi-step instructions, which limits their reliability in production settings. We will introduce agentic monitoring (real-time verification of an agent’s behavior) and reflection (self-checking and revising outputs) as key mechanisms to catch and correct mistakes early to enable scalable, reliable agent deployment in high-stakes applications.

Large language models have come a long way in reasoning and task planning, but building truly reliable AI agents still presents significant challenges. When agents are required to follow detailed, step-by-step instructions—such as planning tasks, using specific tools, or formatting their output correctly—mistakes are common. These can include things like using the wrong format, skipping steps, hallucinating tool calls, or misunderstanding specific instructions embedded in a prompt.
In critical applications, these errors are more than just inconveniences. They can block adoption of AI agents in workflows where correctness is non-negotiable. It becomes essential to verify that agents actually follow their instructions and to have some way to catch mistakes before they cause problems.
Instruction adherence rates for large language models vary depending on the complexity of tasks and the benchmarks used. Recent studies and open evaluations show that even the best models frequently miss parts of complex, multi-step instructions. The table below summarizes instruction-following accuracy for several leading models, along with public sources.
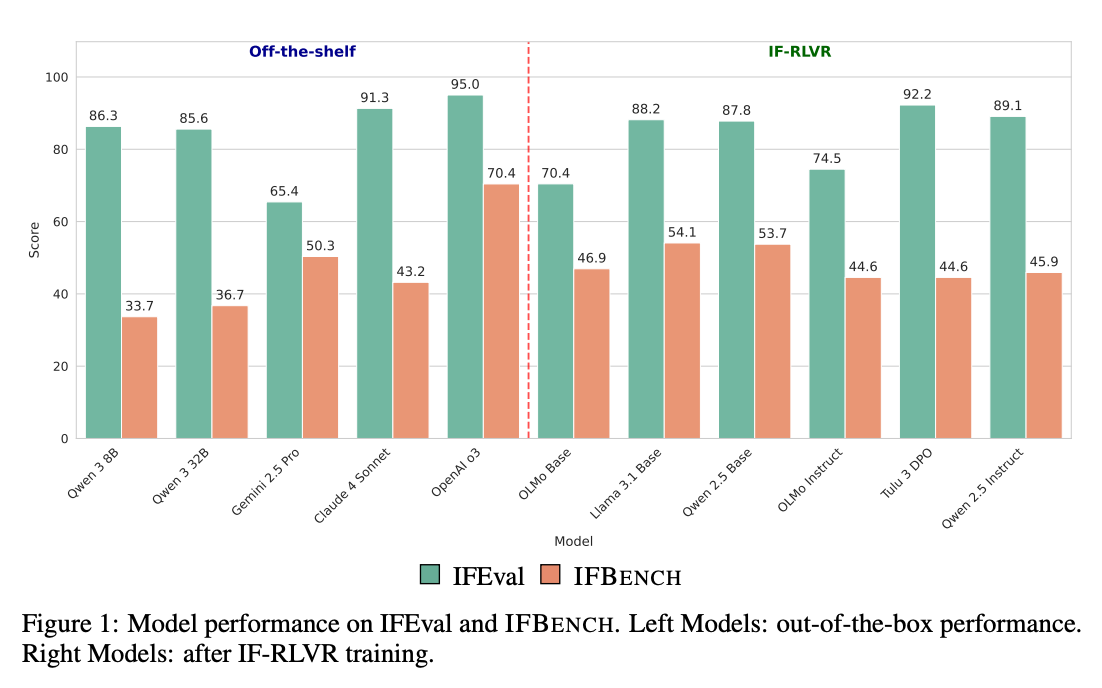 Source: https://arxiv.org/pdf/2507.02833
Source: https://arxiv.org/pdf/2507.02833
These figures highlight the persistent gap between instruction complexity and model reliability, and point to the value of dedicated evaluation tools for ensuring agentic quality in production.
Agentic monitoring means continuously checking whether an agent behaves correctly at every stage of a task, not just at the end. This involves making sure the agent:
Understands the task and instructions
Follows each instruction as intended
Produces output in the correct format
Uses the appropriate tools or data sources
But agentic monitoring must go even further. Beyond instruction adherence, monitoring should also address risks that are central to trustworthy AI:
Agents may generate plausible-sounding but fabricated information—a problem known as hallucination. Continuous monitoring should assess not just whether instructions are followed, but whether the output is grounded in the given data, context, or references. Detecting hallucinations is vital in domains like healthcare, legal, or enterprise automation where spurious outputs can cause real harm.
In some workflows, agents have access to personally identifiable information (PII), confidential business data, or other sensitive material. Monitoring should flag when an agent’s output contains such information—intentionally or accidentally—and enforce policies for redaction or alerting, ensuring compliance with data privacy standards.
A common failure mode is when agents provide verbose, off-topic, or irrelevant outputs. Effective monitoring tracks not just correctness but also whether each response remains relevant to the user’s query or task context, filtering out tangents and unnecessary information.
Other risks include output toxicity, bias, and repeat failures in specific edge cases. A comprehensive agentic monitoring system should be able to detect and mitigate these as well, creating a safety net for high-stakes deployments.

A common approach to improve reliability is the reflection pattern. In this setup:
The agent generates a response.
Before moving on, it checks its own output to see if the instructions were followed.
If something is wrong, the agent tries again by revising or regenerating its response.
This pattern allows agents to fix problems as they happen, rather than passing errors downstream. However, the way reflection is often implemented today has some real drawbacks. Usually, it requires making an extra call to a large language model (like GPT-4) to review each output. This adds significant cost, slows down the workflow by several seconds per check, and the accuracy of these self-evaluations is not always consistent, especially for detailed or specialized instructions.
Consider an agent tasked with summarizing support tickets while following specific constraints—such as keeping user names private, formatting outputs as JSON, or always including ticket IDs. You need to monitor every step to ensure these rules are followed.
If you rely on a general-purpose language model for this evaluation, you face several problems:
Multiple expensive model calls are required
Each evaluation introduces several seconds of delay
You have to carefully engineer prompts just for evaluation
Subtle instruction violations can still slip through
All of this makes real-time, reliable reflection difficult to scale.
AIMon’s IFE (Instruction-Following Evaluation) model addresses these challenges by providing a specialized tool for checking instruction adherence quickly and accurately.
Here are some features that make it practical:
Speed: IFE evaluates outputs in under 200 milliseconds on a single GPU, making it fast enough to run within live agent workflows.
No prompt engineering: IFE can automatically extract instructions from prompts and evaluate outputs without needing custom prompts for each check.
Detailed feedback: For every instruction, IFE provides a score showing how well it was followed, and highlights which parts of the output did not meet requirements.
General applicability: IFE is trained to handle a range of instruction-following tasks across different domains, so you do not need to retrain it for each new use case.
With IFE, it becomes possible to:
Add a reflection step after each key agent action
Instantly check if the agent followed instructions
Retry or log errors automatically if there are problems
Collect data to improve prompt design or train more robust agents in the future
This approach makes continuous, fine-grained monitoring and self-correction realistic for production systems. It transforms reflection from a theoretical idea into an operational tool.
Reliability for agentic systems comes from more than just powerful models or creative prompt design. It requires ongoing verification that every instruction is followed at every step. Monitoring and reflection are essential, but only work at scale with efficient, purpose-built evaluation models.
AIMon’s IFE is designed to meet this need, making it much more practical to deploy agents that must meet real-world standards for accuracy and compliance.
If you’re developing agents for tasks that demand consistent instruction-following, integrating a tool like IFE could make a significant difference.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.