
Wed Feb 21 / Puneet Anand
Read on to learn about why Generative AI requires a new continuous monitoring stack, what the market offers currently, and what we are building

Generative AI models diverge from traditional ML models in their usage and applications. Traditional ML models focus on tasks such as classification and regression, excelling in scenarios such as ranking, sentiment analysis and image classification. In contrast, generative AI models, leveraging architectures like Transformers, specialize in dynamic content creation and augmentation. They are instrumental in generating synthetic images, crafting coherent and contextually relevant text, and dynamically adapting to real-time inputs. , which will allow individual designers, startups and other small teams a chance to create a culture of openness early on.
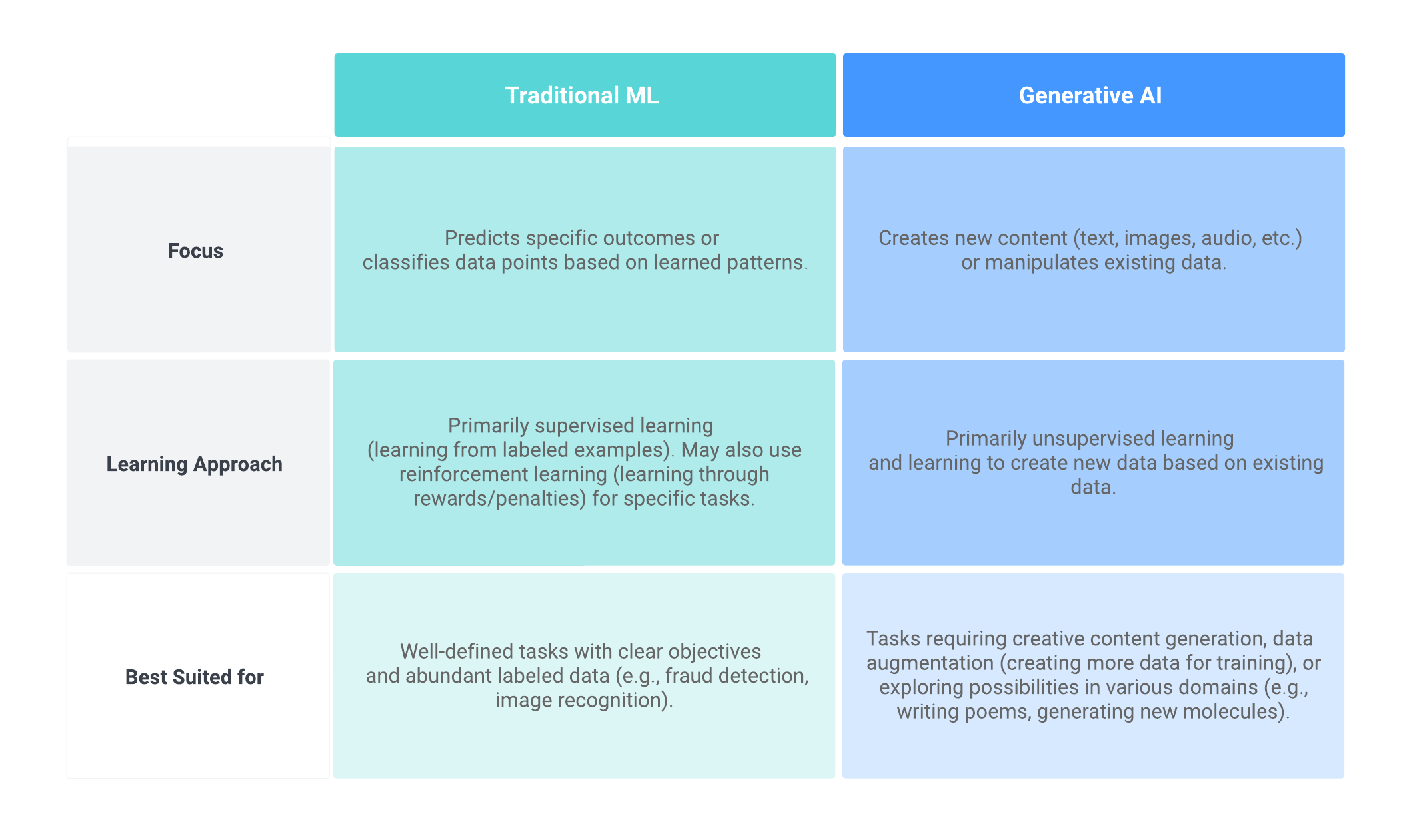
Overview of how Traditional ML models differ from Generative AI models.
Having understood how Traditional ML models are different from Generative AI models, let’s explore the differences from the Observability perspective. Due to the nature of their functions and outputs, there are both similarities and some stark differences. Let’s cover these in a bit more detail:
High-level Similarities (but details matter):
Differences:
Having looked at the Observability aspects of Generative AI and how they compare with Traditional ML, let’s explore whether traditional Observability and Monitoring tools work for LLMs.
A wide range of Traditional ML tools for Observability, Explainability, and Offline/Online Evaluations have been available on the market for a few years now. And some of these companies have been moving into offering basic LLM performance monitoring including system metrics, Data Quality, and Model Quality. Yet it’s very important to note that they are not natively designed to assess real-time factors like hallucinations and completeness, or other pertinent metrics that reflect the quality of LLM outputs.
Offline evaluations help detect LLM quality metrics for ‘golden datasets,’ which consist of a predefined set of prompts, context, and optionally, the ideal answers. These datasets are then used like regression test suites (remember Selenium?) to test the LLMs at a specific point in time or at a preset frequency. Offline evaluations can be very useful if you are in the early stages and experimenting with various LLMs, RAG techniques, prompts, etc., or if you only worry about a static set of prompts to ensure the quality of the top N business use cases. However, if your app’s context or prompts vary greatly, this approach might not work too well. It could be more like capturing a view of the world while wearing large blinders and could potentially have a significant impact on your business.
As the following quote suggests, different factors like prompts and context might induce hallucinations in real-time, which the golden dataset based approaches don’t cover completely.
LLMs are typically evaluated using accuracy, yet this metric does not capture the vulnerability of LLMs to hallucination-inducing factors like prompt and context variability.
The above discussion reminds me of how bad I was at the History class. I would cram the most important questions in preparation for the exam, but I was always boggled by the questions I didn’t prepare for or if the ones I knew were asked differently.
LLMs behave similarly. Imagine an insurance company, called InsuranceAI that sells three products - Home, Automobile, and Renter’s and utilizes AI heavily. This company makes use of LLMs in the following ways:
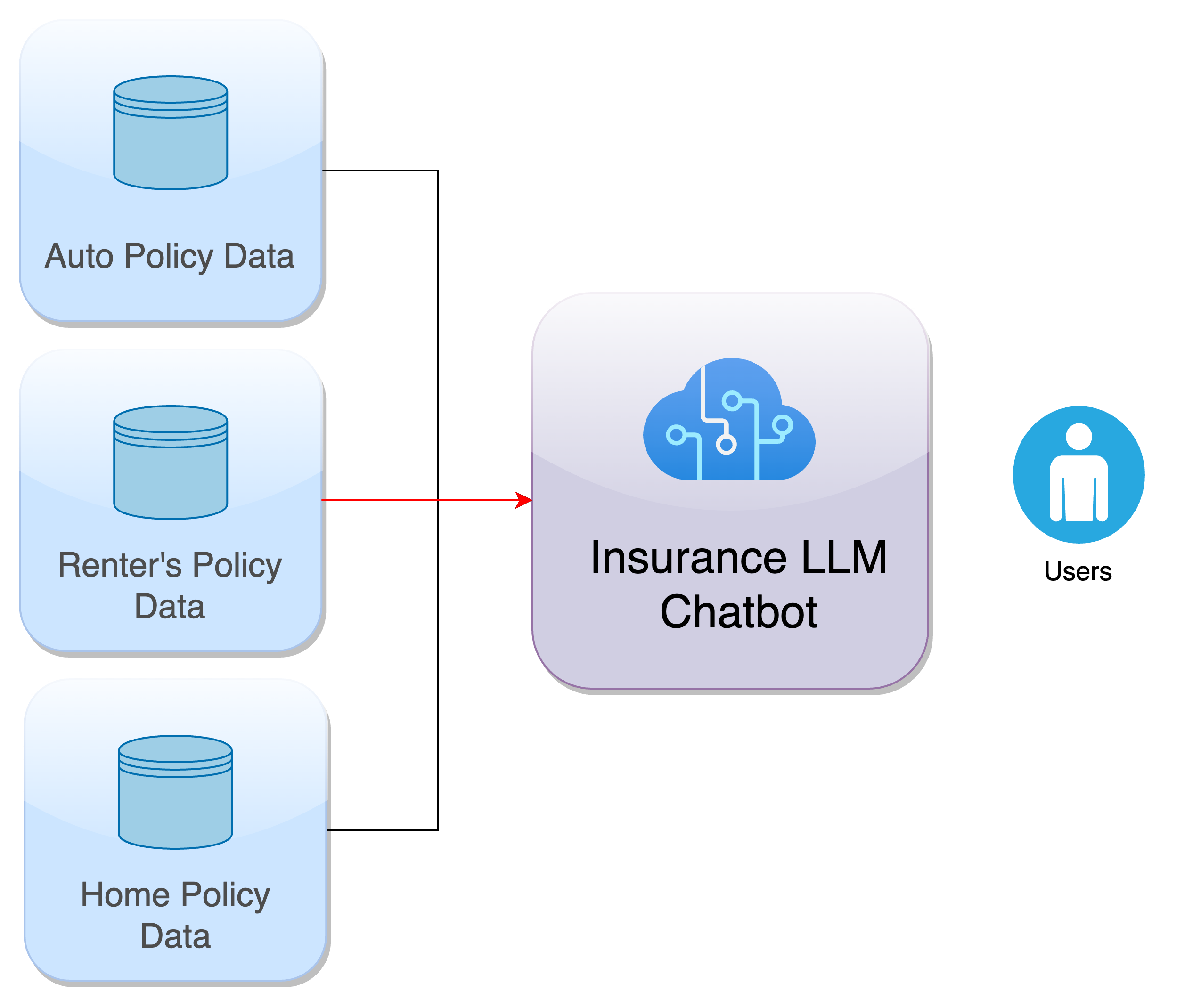
Let us assume the LLMs get a few important facts on Renter’s deductibles wrong, especially when the user asks for a bundled quote (multiple products quoted together). This could happen due to lack of data on Renter’s, poor implementation of fine-tuning or in-context learning (RAG) approaches, or for various other reasons. We would all agree that this will impact existing and new business, brand value, and revenue in a major way. Let me ask you - how, and when should the InsuranceAI ideally learn about this? ASAP or a month later?

Continuous, automated, real-time monitoring for output quality would definitely help them learn about these gaps instantly, and neither would this kind of monitoring require them to proactively figure out each and every aspect that the LLM could get wrong. Why use an LLM if you had to go through all of that in the first place?
I had the good fortune of meeting some amazing customers who utilize LLMs as a core part of their product stack and are very passionate about their user experience, so much so that they manually review 100s of LLM responses every day to evaluate how well they served their customers. This demonstrates the lengths leaders go through to ensure customers have a good experience but also how tedious monitoring LLMs can be in real-time and at large scale. How amazing would it be if this could be replaced with continuous, automated monitoring?
We will be writing more about this topic in the near future, but this is a good segway into what we are building for the industry.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.