
Thu Sep 19 / Puneet Anand
I went to meet a few people around the SaaStr and Dreamforce Conferences in the San Francisco Bay area and found that agentic LLMs are a hot topic in the valley. Let's dive into how agentic LLM frameworks are marking an evolution in artificial intelligence.

Earlier in September, I went to meet a few people around the SaaStr and Dreamforce Conferences in the San Francisco Bay area and found that agentic LLMs are a hot topic in the valley.
Agentic use cases have been mentioned quite a few times during customer conversations at AIMon, so it is a good time to share what I know in an article.
Aside from our interest in this topic, the rise of agentic LLM frameworks is marking an evolution in artificial intelligence architectures by expanding the capabilities of large language models (LLMs) like Llama 3 and GPT 4.
In other words, these frameworks allow LLMs to transcend conventional use cases by integrating reasoning, planning, and tool usage, all of which enable more complex and autonomous decision-making processes.
However, while agentic LLM frameworks present new possibilities, they also face challenges that necessitate careful monitoring and control.
Before we get there though, let’s set the record straight and share some basic concepts around agentic LLMs.
Let’s explore real-world applications where these agentic LLMs enhance productivity and lead the way into smarter, more proactive systems.
Agentic LLM frameworks excel in tackling intricate tasks that require multiple steps and coordination.
For example, when developing software, agentic LLMs can act as an advanced coding assistant, utilizing tools to write, test, and debug code.
In this case, one agent might generate code while another tests and refines it. The result is a more efficient development process.
Agentic LLMs can integrate data retrieval, analysis, and decision-making capabilities, reducing the time and effort required for regulatory compliance, report generation, and risk assessment - all of which are present across most enterprises and industries.
In customer-facing applications like virtual assistants or technical support, agentic frameworks enable LLMs to pull from past conversations and relevant databases and provide personalized, accurate responses.
For example, agents can track user preferences over time and offer tailored solutions based on historical interactions, all while maintaining a natural conversational flow. This use case can be a game changer not just for the sake of efficiency, but also because of the improved support quality.
Traditional (single) LLMs are powerful but have inherent limitations, especially when handling highly complex tasks.
Agentic LLM frameworks, on the other hand, transform LLMs into autonomous agents capable of:
These systems involve multiple agents working together, each with a specialized function, to collaboratively complete complex tasks or workflows.
Here is an example of how a multi-agent LLM system might work in a customer support use case:
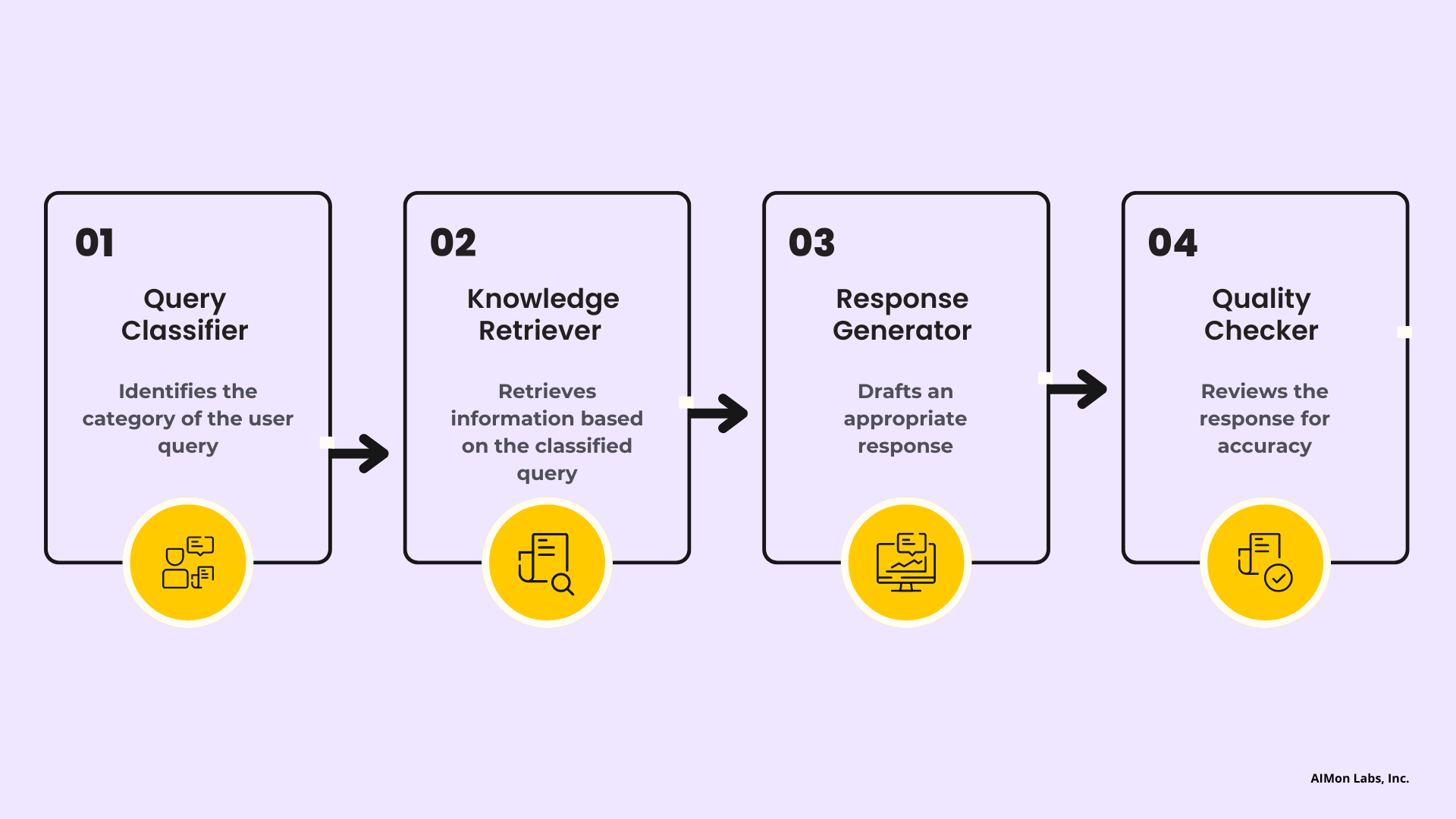
In the graphic above, four different LLM agents are working together:
Several open-source tools and frameworks are available to build and manage agentic LLM systems. Here are some of the leading ones:
| Framework | Pros | Cons | Best for |
|---|---|---|---|
| AutoGen | Customizable. An active community for support. Provides support for human feedback to guide agents. | Harder to setup. Difficult to implement complex tasks. | Large-scale applications that integrate multiple agents. |
| CrewAI | Built on Langchain. Fast setup. Modular design. | Built on Langchain, a heavy package with a lot of dependencies. Nested, parallel crews are not supported yet. | Great for prototyping and getting started quickly. |
| LangGraph | Official Langchain, Inc. product. Focuses on task modularization through a graph-based concept aiming for scalability. | Requires knowledge of graph theory for setup, resulting in a steep learning curve for many users. | Complex workflows where task interdependencies are critical. |
Other notable mentions:
When it comes to LLM Agentic frameworks, the ecosystem is still evolving.
I have seen many teams use LlamaIndex and Langchain to write custom internal code and address specific needs - and that works really well, too.
Despite their promise, agentic LLM frameworks present a few limitations, including:
Response latency: As tasks become more complex, and agents communicate and exchange information, response times tend to increase, turning any real-time use case into a challenge.
Costs: The more LLMs you deploy, the higher the cost. And the more they interact and call external tools, the higher the cost too. It can go even higher if you rely on particularly costly APIs! This may deter widespread implementation for tasks that aren’t high-value.
Alignment and control: Autonomous agents can stray from their intended goals if not properly aligned with business objectives. This is particularly relevant because many of these agents make decisions in dynamic environments.
Since multi-agent frameworks involve complex interactions, tool integrations, and autonomous decision-making, testing and monitoring are particularly relevant tasks.
Here are several approaches that may be tailored for agentic LLM architectures:
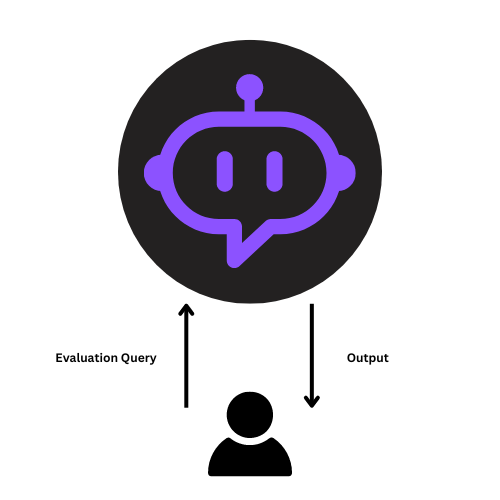
Each agent in the system should be treated as an atomic functional unit. The unit testing process ensures that each agent performs its task accurately.
Some key questions to think about:
Testing multiple agents
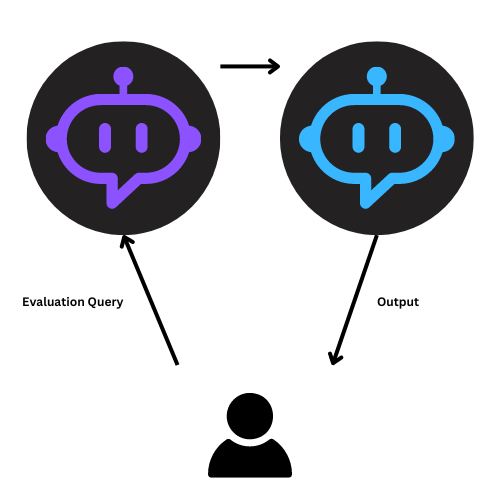
This is where you test slightly more complex tasks that require two (or more) agents working together.
Some key questions to think about:
Can you simulate real-world, end-to-end workflows that require multiple agents to interact and give you the desired output? For example, test workflows where one agent generates a code snippet and another validates or writes tests for it.
How do you ensure one agent’s failure doesn’t cascade to other agents? For example, if one agent hallucinates, how do you detect that, and bake in a remediation?
Given the autonomous nature of agentic LLMs, periodic human intervention evals offer a valuable layer of safety and accuracy.
I highly recommend implementing a HITL approach for critical and high-stakes decisions that can significantly impact your business.
Real-time performance monitoring: Track the performance of each agent in real-time, such as response times, tool integration latency, and API usage.
Monitoring helps optimize resource usage and catch bottlenecks.
Stress testing: Test the system under extreme conditions (e.g., high API usage or long workflows) to identify potential failure or performance degradation.
It is no news that LLMs can hallucinate, ignore instructions, or produce irrelevant responses.
When you chain together multiple LLMs, the stakes get much higher. So what can we do to guard against these risks?
Implement guardrails and validation mechanisms: An option is to deploy post-processing agents that verify the factual correctness of responses using contextual data, such as databases or internal knowledge. AIMon offers lightweight models that work at GPT 4 level accuracy but provide you sentence and passage level detection scores in under 300ms.
Introduce continuous feedback and remediation loops where agents’ outputs are monitored and evaluated in real time. For example, a tool like AIMon or another LLM agent may validate an agent’s result using a predefined quality metric (i.e. deviation from instructions) providing a continuous check on decision accuracy, which can then be used to reinvoke the agent with feedback.
Agentic LLM frameworks hold immense potential for automating complex tasks and enhancing human-machine interaction.
At the same time, they also present certain risks and challenges related to correctness, control, latency, and costs that need to be meticulously managed.
By leveraging platforms such as AutoGen, CrewAI, and LangGraph and implementing continuous oversight and remediation using tools like AIMon, developers can build powerful, accurate, and efficient agentic systems that unlock new high-impact use cases.
The key to successful implementation lies in continuous oversight, ensuring that agent systems operate within their intended bounds while delivering optimal performance.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.