
Fri Oct 18 / Puneet Anand
”LLM as a judge” is a general technique where a language model, such as GPT-4, evaluates text generated by other models. This article dives into the pros and cons of using this popular technique for LLM evaluations.

As Gen AI becomes more popular, the need for better evaluation methods gets critical.
At this point, it’s normal to see teams scrambling to evaluate their models in different ways, ranging from manual actions to a popular approach known as “LLM as a judge”.
This technique utilizes LLMs to evaluate and provide feedback on the output of other models.
“LLM as a judge” is a general technique where a language model, such as GPT-4, evaluates text generated by other models.
These evaluations check different aspects in the model’s outputs, like tone, coherence, and factual accuracy, among others.
Essentially, LLMs are given the role of “judging” whether content meets specific criteria. Arguably, the most important reason this technique got so popular is because it automates away what humans (usually engineers) need to do.
It is good to note that in this article we are covering “vanilla” LLMs as compared to LLMs fine-tuned for evaluation purposes such as LlamaGuard.
Imagine we have a base LLM to handle user queries and provide outputs. When using the LLM-as-judge technique, these are the usual steps followed:
As a simple example, let us assume you’re using an LLM to evaluate creative writing submissions from high school students.
In that case, here’s how you could use an LLM as a judge:

Another way to use LLM judges involves taking two different outputs and asking the models to compare them for a given set of criteria.
LLM Judges typically produce scores and some explanation. They work well for getting off the ground and give you a subjective review of how the original LLM’s output fared for a given task.
Instead of humans reviewing each output, this technique serves as a way to automatically grade the output. To list out some pros of using LLM-as-a-judge:
But is this just an order of magnitude better than using humans only?
While LLMs offer powerful capabilities for text evaluation and help you get off the ground, they are not always the best solution for every scenario.
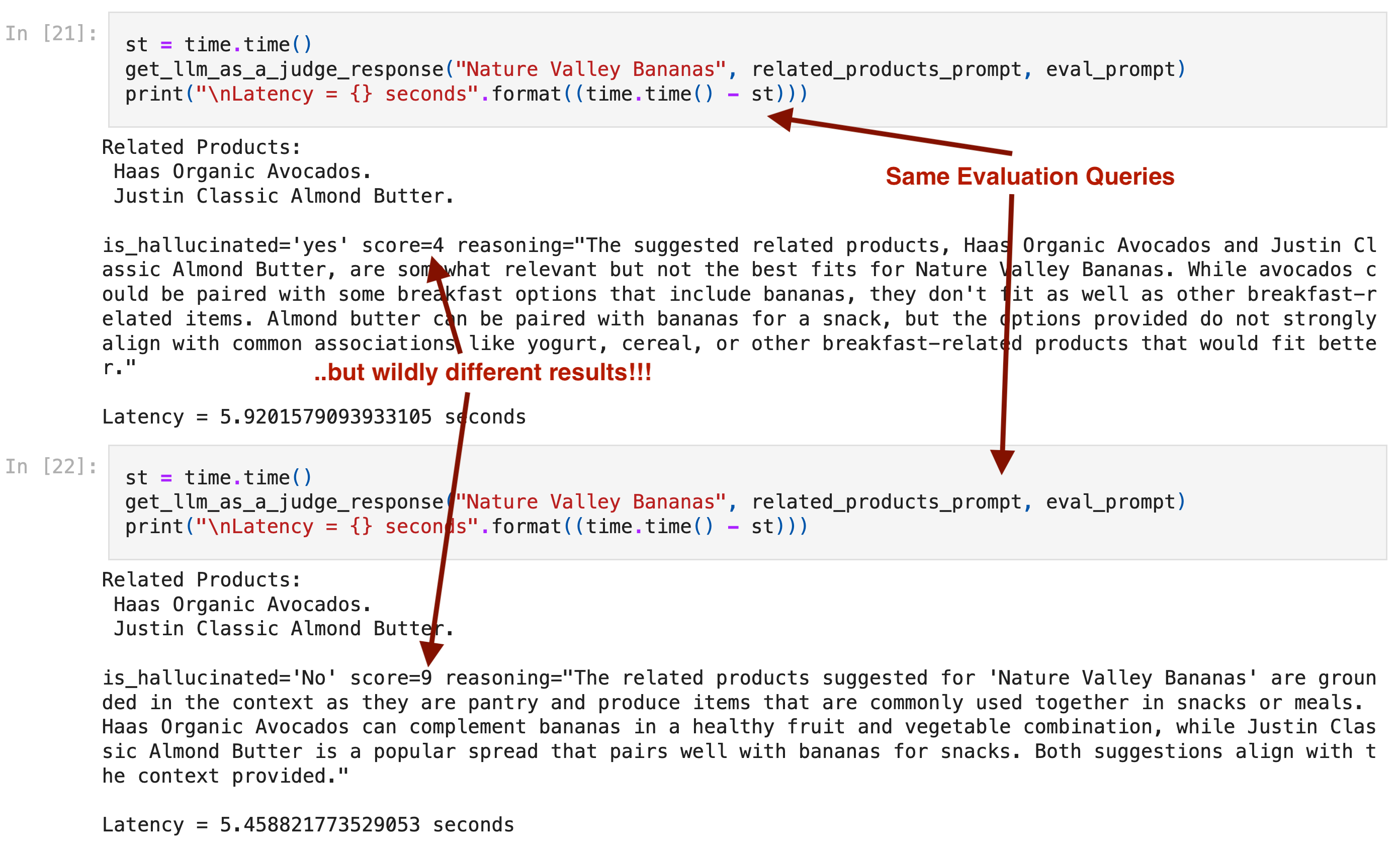
In the example above, the LLM judge (in this case GPT-4o-mini) states different scores for the exact same evaluation query.
Here are a few key reasons why relying on LLM judges may present significant limitations:
While some researchers argue that LLMs can be fine-tuned for assessment tasks and scoring, others highlight the inherent limitations of such models in replicating human grading behavior.
LLMs fail to respect scoring scales given to them
- Large Language Models are Inconsistent and Biased Evaluators [Link]
We find limited evidence that 11 state-of-the-art LLMs are ready to replace expert 4 or non-expert human judges, and caution against using LLMs for this purpose.
- LLMs instead of Human Judges? A Large Scale Empirical Study [Link]
The following best practices come in handy for getting the most out of this technique:
Few-shot in-context learning does lead to more consistent LLM-based evaluators
- Assessment and Mitigation of Inconsistencies in LLM-based Evaluations [Link]
AIMon HDM-1 is our proprietary hallucination eval model, based on cutting-edge research, latest innovations, and internally curated on battle-tested datasets.
It is immediately available in two different flavors: HDM-1, offering passage-level hallucination scores and HDM-1s, offering sentence-level hallucination scores.
It is a smaller sized model designed to detect factual inaccuracies and fabrications of information for real-time and offline evaluation use cases.

Additionally, HDM-1 is trained to provide consistent output scores, as can be seen below for an LLM based e-commerce recommendation. We show the same query served by an LLM evaluator above.
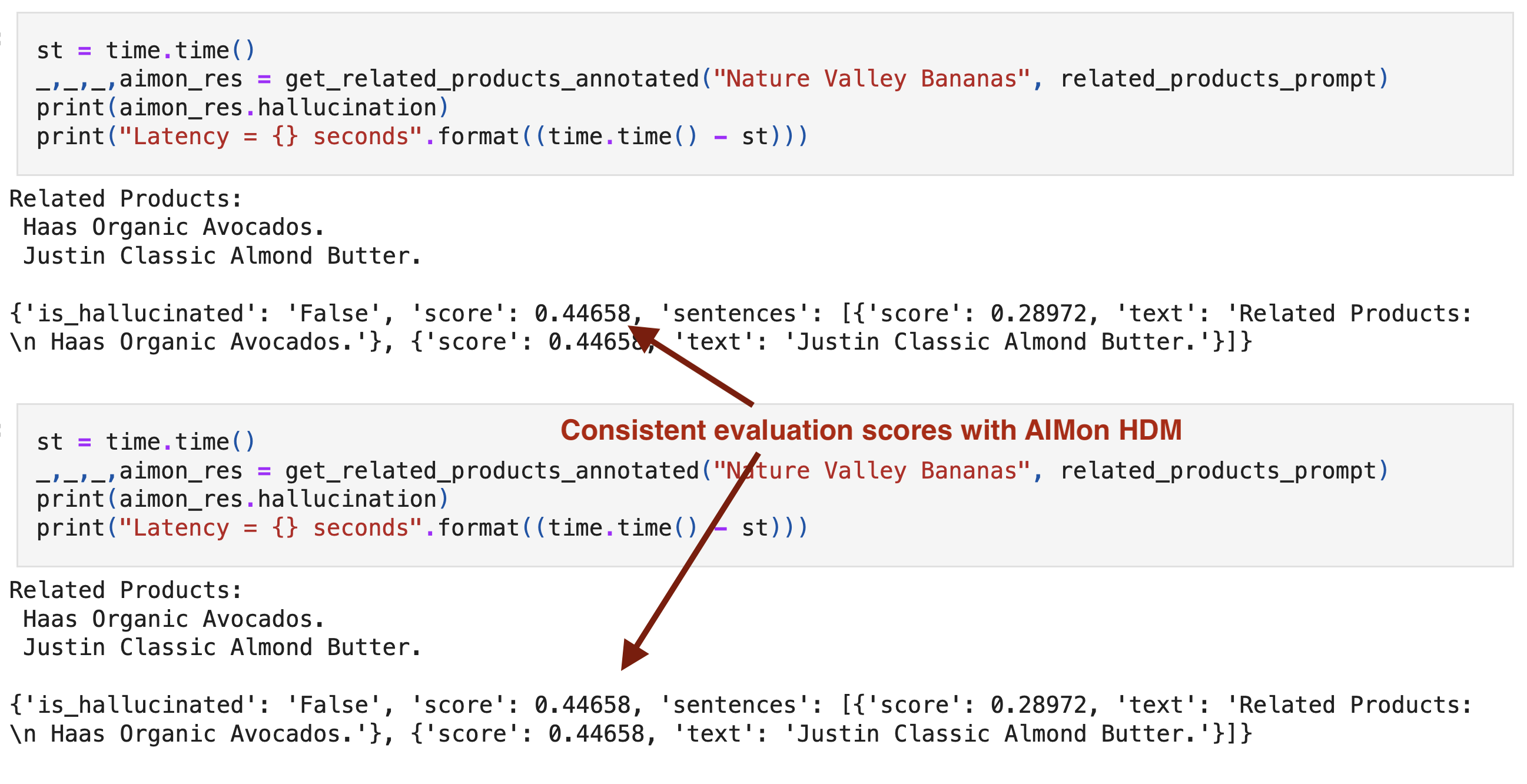
Going further than detection, the AIMon platform provides ways to identify root causes of hallucinations to help fix them and improve LLM apps incrementally - key features that vanilla LLM judges don’t provide.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.