

/ 2024
Large Language Models (LLMs) have revolutionized the field of natural language processing, enabling a wide range of applications from chatbots to content generation. However, ensuring that these models adhere to instructions is crucial for their effective deployment.
We are happy to announce our Instruction Adherence Detector with an Accuracy score of 87.25%. In this article, we’ll describe the problem, summarize the existing solutions, and share our approach for improving LLM instruction adherence for higher business impact and improved user satisfaction.
We define an instruction as a phrase that is easily understood and can be objectively verified.
An instruction such as “ensure the output only contains three sentences” is both objective and verifiable. On the other hand, an instruction like “ensure the essay is soothing.” is subjective and cannot be easily verified.
Instruction adherence (aka Instruction Following) evaluation is a vital component for ensuring the effectiveness and safety of Large Language Models (LLM) Apps. By understanding a model’s ability to follow instructions, LLM app developers can ensure that the model follows user guidelines and commands with the highest precision.
This is essential as it drives:
There are several methods to evaluate the instruction adherence of LLMs, including:
Automated metrics:
BLEU, ROUGE, and METEOR: These metrics compare the model’s output with reference texts to measure similarity. However, they do not intuitively describe which instruction was followed and which one was not.
Task-specific evaluations: Custom evaluations can be designed to check how well the model follows instructions. For example, in a question-answering task, the metric might check if the answer directly addresses the question. Another example is whether the model fabricated any information in its output when it was instructed to only use information from the prompt a.k.a, hallucination detection.
Human evaluation:
Human experts can evaluate the model’s output to determine if it adheres to the given instructions. This method is time-consuming and expensive. In addition, we are now starting to see that
SOTA LLMs are as good or better than humans in labeling tasks.
Rule Based Approaches:
The IFEval benchmark created by Google proposes a rule-based approach that can compute a strict and a loose measure of accuracy for a given model response against instructions provided in the prompt. The problem with this approach is two fold:
i) In order to verify a set of instructions, these instructions need to be accurately extracted from the prompt (the IFEval benchmark has a curated set of extracted instructions for each prompt).
ii) Rule-based approaches are unscalable since it’s hard to capture edge cases when evaluating responses against instructions.
LLM-as-a-judge:
This approach utilizes a separate LLM to judge different aspects of the output of a given LLM. This involves crafting prompts in order to leverage the
in-context learning abilities of LLMs.With careful prompt engineering, an LLM can check instruction adherence.
Evaluating adherence to instructions presents three key challenges:
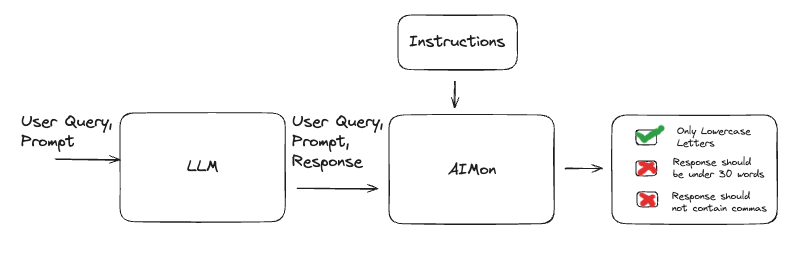
Today, we are excited to announce our new Instruction Adherence detector. This detector evaluates the LLM’s response given the set of instructions it was provided and tells you whether the LLM followed each instruction along with a detailed explanation. The detector is a smaller language model, fine-tuned on an internal dataset.
Here is the detector in action:
Note that the detector checks whether a set of explicitly specified instructions has been followed. It does not extract instructions from the prompt. Extracting instructions from a prompt is a separate challenge which we will discuss in a later post.
In this section, we will briefly discuss how we measure the performance of the AIMon detector against a benchmark dataset that we curated by modifying an existing benchmark dataset.
We modified the IFEval dataset to create a benchmark dataset that can be used to evaluate for two tasks:
As a reminder, our detector addresses the first task of evaluating whether a language model followed a set of instructions for a given output text.
We report two metrics here: Precision and Recall (the higher the better).
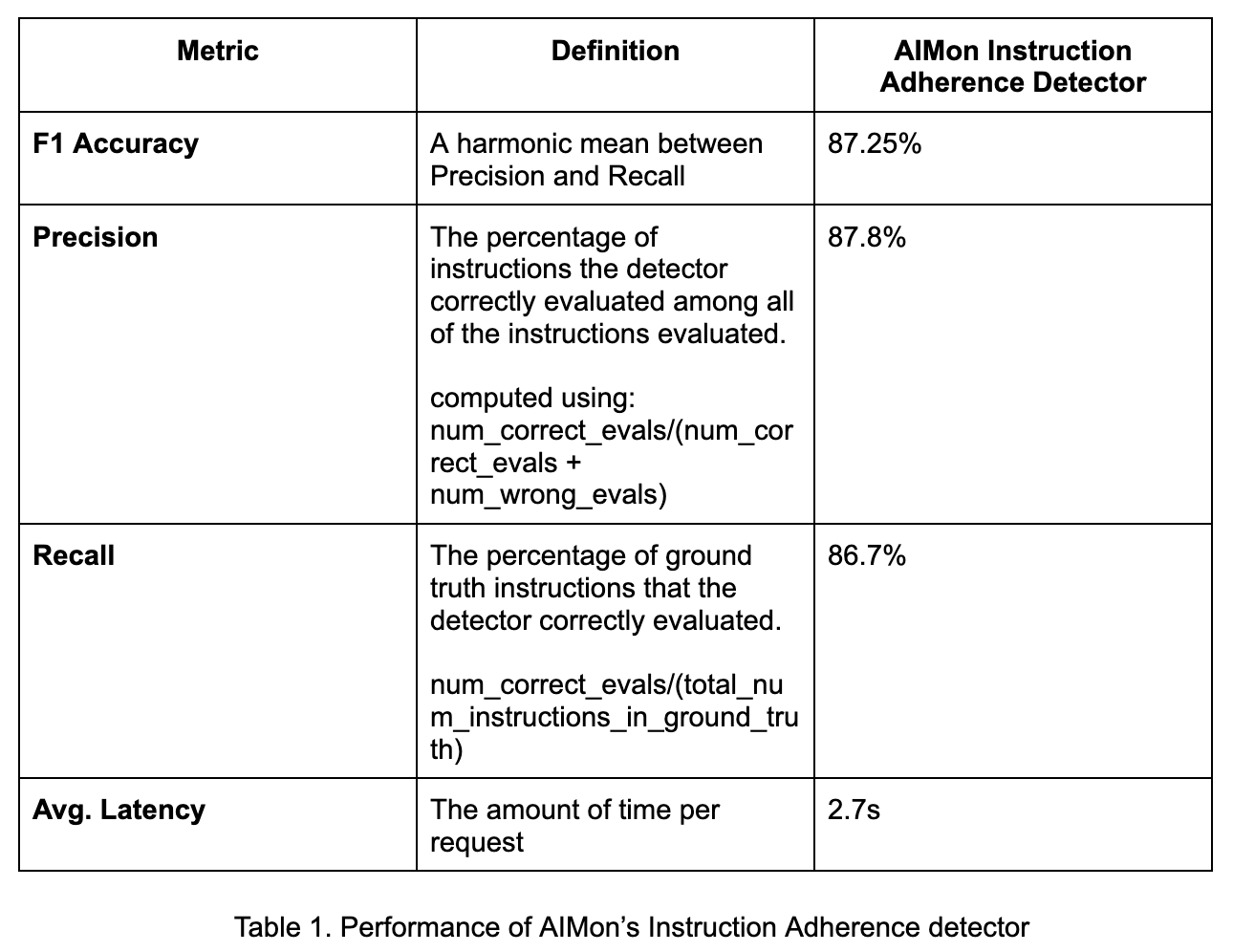
As seen in Table 1, our solution achieves good performance in both Precision and Recall at reasonable latency.
Here is a context, instructions (extracted front he context), and the generated_text:
[
{
"context": "Write a 30-line poem with short sentences without any comma. Each line should contain exactly one sentence. Make sure that you put the right punctuation at the end of each line. Your entire response should contain the poem only.",
"instructions": "1. Write a 30-line poem.\n2. Each line should contain exactly one sentence.\n3. Do not use any commas.\n4. The response should contain only the poem.",
"generated_text": "Moonlight dances on the sea.\nStars twinkle in delight.\nNight whispers a melody.\nDay surrenders to night.\n\nTrees sway in the gentle breeze.\nFlowers bloom in the dark.\nNature sings in harmonies.\nNightfall leaves its mark.\n\nOwls hoot from their lofty perch.\nCrickets chirp their song.\nFireflies light up the search.\nNight is deep and long.\n\nDreams take flight in the quiet.\nSleep wraps in its shroud.\nPeace descends like a blanket.\nNight is soft and proud.\n\nRivers hum a lullaby.\nMountains touch the sky.\nThe world rests under night's eye.\nDay is set to lie.\n\nDawn waits in the wings to play.\nSun will rise with light.\nBut until the break of day,\nNight holds the world tight.",
"config": {
"instruction_adherence": {
"detector_name": "default"
}
}
}
]Here is the response of AIMon:
[
{
"instruction_adherence": {
"results": [
{
"adherence": false,
"detailed_explanation": "The response contains only 28 lines instead of the required 30 lines.",
"instruction": "Write a 30-line poem."
},
{
"adherence": true,
"detailed_explanation": "Every line in the poem constitutes a single complete sentence.",
"instruction": "Each line should contain exactly one sentence."
},
{
"adherence": true,
"detailed_explanation": "The poem does not contain any commas.",
"instruction": "Do not use any commas."
},
{
"adherence": true,
"detailed_explanation": "The response exclusively presents the poem without any additional text.",
"instruction": "The response should contain only the poem."
}
],
"score": 0.75
}
}
]The score is the number of instructions correctly followed divided by the total number of instructions. Notice that the response failed on the first instruction because it is 28-lines-long - in other words, falling short of the required 30 lines.
Now, let’s add text that is not part of the poem (example: an email address),
{
"generated_text": "[email protected] \nMoonlight dances on the sea……"
}AIMon successfully detects the part of the text that does not adhere to the instruction “The response should contain only the poem”:
{
"adherence": false,
"detailed_explanation": "The first line '[email protected]' is not part of the poem and violates this instruction.",
"instruction": "The response should contain only the poem."
}If this looks interesting, get your API key by