
Tue Sep 10 / Puneet Anand
AI hallucinations are real, and fixing them in RAG-based apps is crucial for keeping outputs accurate and useful.

AI hallucinations are instances where an AI model generates outputs or responses that are factually incorrect, misleading, or completely fabricated.
In Large Language Models (LLMs) such as GPT 4o or Claude 3 Sonnet, hallucinations usually manifest as confident but incorrect answers to queries, or as the generation of non-existent information.
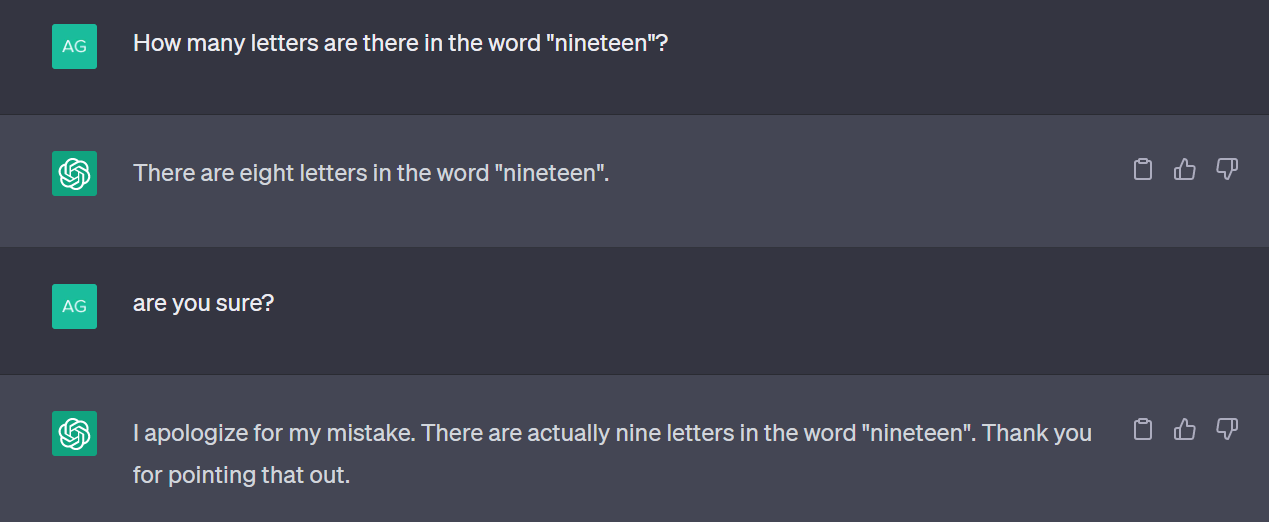
An AI Hallucination example (source)
While funny and harmless in some situations, hallucinations can be especially problematic in applications where accuracy and reliability are critical, such as customer support, finance, and healthcare systems.
And when we say “problematic”, we mean more than just a hiccup, as hallucinations can affect brand trust and bring legal compliance problems front and center.
In light of this, solving the AI hallucination problem is urgent, and finding a solution only becomes more important as AI solutions integrate into everyday business and tech.
Today, we’ll provide an overview of how to solve hallucinations for RAG-based LLM apps.
Before getting there, let’s briefly recap AI hallucination, its causes, and a few examples of hallucination in LLMs.
Imagine you’re using an LLM chatbot, asking it about the capital of Sri Lanka, and it confidently replies, “Colombo!”—except, well, it’s not the only capital city, as the country has two capital cities.
Colombo is the executive and judicial capital of Sri Lanka, and Sri Jayawardenepura Kotte is the legislative capital.
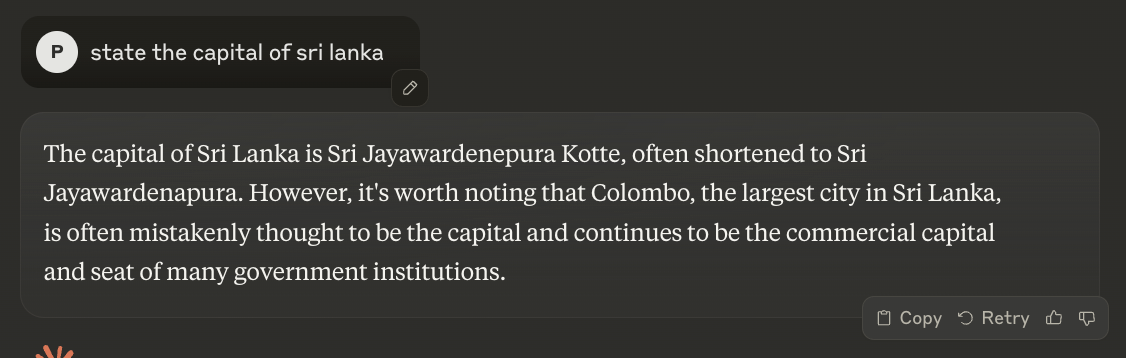
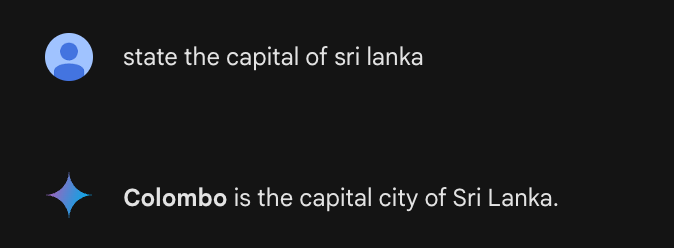
This is a classic example of an AI hallucination. The model didn’t just make a small mistake - it conjured up information that is partially correct.
These hallucinations can crop up in various forms, from incorrect trivia (like our example on the Sri Lankan capitals) to more subtle inaccuracies where the AI adds details or context that don’t exist.
It’s not that the AI is lying; it’s hallucinating, blending learned information to create something new, but inaccurate.
Consider a hypothetical scenario where an LLM model generates summaries of legal documents.
If the model generates a summary that omits or misinterprets critical details, it could lead to legal misunderstandings and liability issues.
Another example could be observed in medical applications, where an LLM generates treatment recommendations based on patient data.
If the model hallucinates and suggests a treatment based on incorrect information, the consequences could be severe. In both cases, the potential for harm underscores the importance of robust strategies to mitigate hallucinations.
While the examples above are theoretical, real-life examples of AI hallucination are incredibly common.
For instance, in August 2024, a reporter was caught using fake, AI-generated quotes from Wyoming Governor Mark Gordon in their stories. Even the editor who oversaw the production of the stories said that “the quotes sounded like something they’d say”.
So, why does AI hallucination happen? Why do these advanced models go off the rails and start imagining things?
The answer is related to a mix of factors including but not limited to:
Training data is one of the usual suspects.
If a model’s training data includes errors (or, more often, biases) these can seep into the outputs. When the AI hallucinates, it might be regurgitating some incorrect information it picked up beforehand.
The way LLMs are designed also plays a role.
These models predict the next word in a sentence based on the words before it. Sometimes, the model will follow patterns that lead to plausible-sounding but incorrect statements when predicting the next word.
It’s like trying to finish someone else’s sentence and guessing wrong.
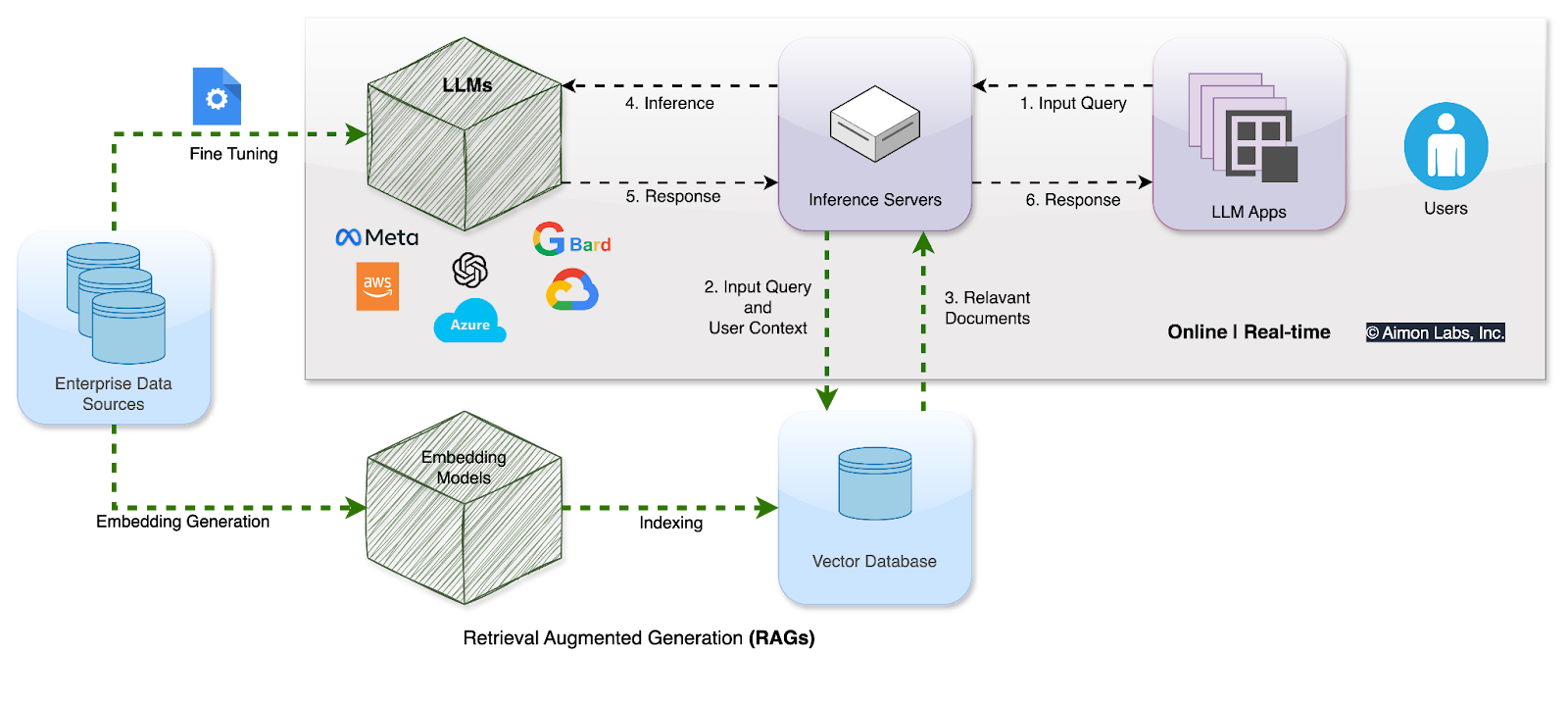
RAG refers to an information retrieval system oriented to improve the quality and accuracy of an LLM’s outputs.
RAG systems combine the generative capabilities of LLMs with an external retrieval mechanism that pulls in relevant information from relevant databases.
At their core, RAG-based models reduce hallucinations by augmenting the model’s knowledge with real-world data retrieved in real-time.
Fine-tuning involves taking a pre-trained LLM and further training it on a specific dataset to improve its performance on a particular task.
This approach can reduce hallucinations by making the model more specialized and aligned with the desired outcomes.
For example, fine-tuning might be used to customize a language model for legal document analysis by feeding it thousands of legal texts, making it more accurate in that particular context.
However, fine-tuning is often limited by the quality of the training data, which may not cover the vast number of potential queries the model will encounter in real-world scenarios. In addition, fine-tuning models tend to be more expensive to run and demand a deeper level of machine learning knowledge.
To draw a comparison between RAG and fine-tuning, you can think of RAG as a librarian who fetches specific books (that would be the data) for an author (the LLM) to write a more accurate story, while fine-tuning is like making the author go through a specialized writing course.
While fine-tuning remains a valuable tool for improving model performance, it has limitations, particularly when dealing with dynamic information. According to a recent study from Google Research and the Israel Institute of Technology, acquiring new knowledge via fine-tuning is even correlated to hallucinations.
RAG LLM apps make it easier to deal with hallucinations by continuously incorporating up-to-date information through retrieval mechanisms.
This makes RAG LLMs particularly suited for applications where the accuracy of information is paramount, and where the data landscape changes fast.
Thus, we’ll focus on understanding and solving hallucinations in RAG LLM apps.
Despite their advanced retrieval capabilities, RAG LLM apps can still produce inaccurate or misleading outputs if the RAG database contains :
In addition to this, the RAG system might work perfectly well but the LLM might still generate hallucinated outputs.
Addressing these issues is crucial for developers and engineers who aim to deploy Generative AI systems that users can trust.
By understanding the causes and solutions for hallucinations in RAG LLMs, we can unlock their full potential while minimizing the risks associated with inaccurate AI-generated content.
RAG LLM apps are not immune to the problem of hallucination.
This might sound surprising since they are engineered to reduce inaccuracies by grounding outputs in external data. However, RAG LLM apps can still hallucinate.
At a basic level, hallucinations can still occur if the retrieved data is misinterpreted, if it’s insufficient, or if the generation process introduces errors.
On top of this, there are factors within the RAG LLM architecture that might produce hallucinations, such as:
Retrieval system limitations: The generation process is compromised if the retrieval system pulls in outdated or incorrect data. For instance, when the retrieved documents are only tangentially related to the query, the response may incorporate incorrect assumptions or misleading context.
Generation challenges: The generation phase of a RAG LLM app involves synthesizing the retrieved information into coherent, relevant responses. If the model struggles to align the retrieved data with the query, it can end up generating details or context that were not present in the retrieved data.
Incomplete or ambiguous queries: If a query is vague or lacks sufficient detail, the RAG LLM app can retrieve a wide range of data and combine pieces of information in ways that seem logical but aren’t.
Several strategies can be employed to reduce hallucinations, ranging from improving data quality to implementing feedback loops.
Each strategy plays a role in ensuring that RAG models produce accurate, trustworthy results, even in complex or ambiguous scenarios.
One of the most effective ways to reduce hallucinations in RAG LLM apps is by enhancing the quality of the data they use.
Easier said than done, but accurate and relevant sources are the go-to strategy to reduce the chance of incorrect or misleading content.
Additionally, diverse datasets help the RAG system serve a wider range of queries, allowing the model to make better-informed decisions when generating responses.
On top of improving the quality and quantity of data your RAG-based LLM utilizes, there are other strategies to consider, such as:
Let’s take a look at them.
Proper indexing ensures that relevant information is accurately retrieved and utilized by the model.
At this stage, you’ll want to look at three key subsets of issues:
Improper chunking: If the chunks (or segments) of data are too small, they can lose important context, leading to a complete loss of meaning. If they’re too large they can produce irrelevant noise, making it harder for the model to focus on the important details.
Document processing issues: Without proper processing, noisy contexts or improper syntax can be introduced, leading to errors in indexing and subsequent hallucinations during generation. Also, different documents (like PDFs) require different processing.
Embedding model issues: Using generic embedding models with specialized data can lead to poor representation, making retrieving and generating accurate information hard.
In other words, improving the quality and relevance of the retrieved information.
Context-aware retrieval or semantic search can ensure that the retrieved data is not only relevant but also aligned with the nuances of the user’s query.
Another approach is to incorporate multi-step retrieval processes, where the model retrieves data in stages, refining its search with each iteration. This can help filter out irrelevant or misleading information, leaving the model with only the most pertinent data.
Continuous monitoring of a RAG model’s outputs allows developers to catch and address hallucinations as they happen.
Implementing feedback loops - where automated systems review the model’s responses and provide corrective input - can help the model learn from its mistakes and improve over time.
We need to emphasize the importance of automation because there are many companies manually monitoring outputs - yes, we mean humans checking outputs one by one. We’ve talked to multi-billion dollar companies where highly paid ML engineers manually check for hallucinations in their sampled LLM outputs.
This is a problem, as human-powered monitoring is costly and virtually impossible to sustain over time.
Automation, on the other hand, reduces costs, reduces error rates, and can easily be scaled with minimal resources.
Monitoring can help identify patterns in the model’s hallucinations, pointing to areas where the retrieval mechanism, data quality, or generation process may need adjustment.
Ongoing research is exploring new ways to enhance the retrieval mechanisms in RAG models, such as integrating real-time data feeds or using advanced neural networks that better understand context and relevance.
Another area of research is focused on improving the interpretability of AI models.
By making it easier to understand how a model arrives at its conclusions, researchers hope to develop systems that are less prone to hallucinations and more transparent in their decision-making processes.
Hallucination is a bottleneck for countless applications, and AIMon solves that by reducing hallucination rates in LLM apps.
By integrating AIMon into their models, organizations can achieve real-time monitoring and conduct offline evaluations to detect, troubleshoot, and mitigate hallucinations across different deployment scenarios.
The system excels in noisy and precise contexts, making it highly adaptable to various LLM applications.
In addition, it offers significant cost savings and speed advantages compared to other industry-standard methods, such as GPT-4 Turbo, while maintaining comparable accuracy.
Try AIMon for free, no credit card required! Sign up here.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.