Fri Mar 14 / Devvrat Bhardwaj
GraphRAG combines structured knowledge graphs with traditional retrieval methods to improve context, reduce hallucinations, and enable complex reasoning in LLM applications.
GraphRAG (Graph-based Retrieval Augmented Generation) is emerging as a transformative technique for enhancing large language model (LLM) applications. By integrating structured knowledge graphs with traditional retrieval methods, GraphRAG not only enriches context for complex queries but also mitigates challenges such as hallucinations and error propagation. Industry leaders, including LinkedIn, Google and Microsoft, are already exploring the integration of GraphRAG into their projects, highlighting its growing relevance in real-world applications. These applications range from financial data analysis to complex legal research, where retrieving contextually rich and accurate information is crucial.This blog post weaves together insights from a recent AIMon fireside webinar. We present both theoretical and empirical findings from recent research.
Retrieval-Augmented Generation (RAG) enhances language models by retrieving relevant external documents to improve response accuracy. Rather than relying solely on pre-trained knowledge, RAG fetches information from vector databases—repositories that store embeddings (numerical representations of words, sentences, or documents)—and integrates it directly into the generation process. This mechanism allows LLMs to remain updated and context-aware, particularly in dynamic domains.
However, while vector-based retrieval is effective for similarity searches, it has inherent limitations. Vector search alone often struggles when queries require a deeper understanding of structured relationships between entities. Several studies have highlighted key challenges in traditional RAG systems, such as retrieval inaccuracies, suboptimal ranking mechanisms, and difficulties in handling complex, multi-hop queries. To address these challenges, tools like AIMon’s RAG Relevance Evaluation and Reranker (RRE-1) have been developed, which diagnose retrieval issues and detect context relevance. By providing actionable feedback, these tools help align retrieval processes more effectively with the nuanced demands of complex queries.
GraphRAG transforms the retrieval process by constructing a structured knowledge graph. This graph links entities and their properties, enabling a multihop inference process that connects various pieces of context in a more nuanced manner.
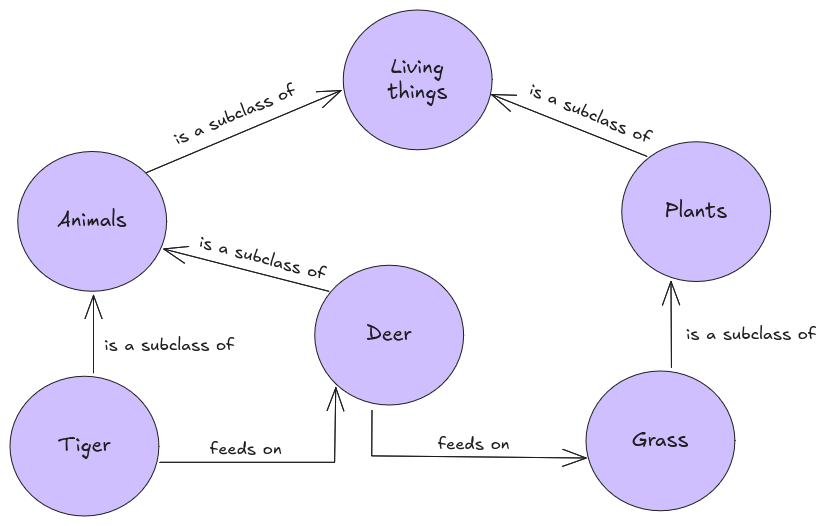
Figure 1. Depiction of a knowledge graph.
For instance, when a query indirectly refers to an entity’s attributes, standard RAG might miss the underlying connections. GraphRAG, however, can navigate multiple related nodes to form a coherent response by leveraging the relationships inherent in the graph structure. This not only enhances the quality of responses but also minimizes the risks of hallucinations—a recurring challenge in LLM applications. For example, consider a user asking, “What animals depend on grass for survival?” A traditional text similarity-based RAG system might return documents mentioning deer only. However, in a knowledge graph like the one shown in Figure 1, GraphRAG can follow structured paths: Grass → feeds → Deer and Deer → feeds → Tiger, revealing an indirect dependency where Tigers, although carnivores, indirectly rely on Grass via their prey.
The hybrid nature of GraphRAG is central to its success. While text-only methods capture broad semantic similarities, they often lack the depth needed for complex queries. GraphRAG supplements this by embedding structured relationships—mapping each entity within a graph that details its properties and interrelations. Recent research has validated this approach, demonstrating that such integration allows GraphRAG systems to scale more effectively with increasing model sizes and dataset complexities.
By merging these two paradigms, GraphRAG achieves the best of both worlds: the precise contextual cues provided by structured knowledge and the wide-ranging matching capabilities of vector embeddings. This synergy is particularly beneficial when addressing domain-specific queries where nuanced understanding is essential.
A key strength of GraphRAG lies in its modular architecture. Rather than relying on a one-size-fits-all solution, GraphRAG comprises several interdependent modules:
from llama_index.core import StorageContext
from llama_index.graph_stores.nebula import NebulaGraphStore
graph_store = NebulaGraphStore(
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import KnowledgeGraphRAGRetriever
graph_rag_retriever = KnowledgeGraphRAGRetriever(
storage_context=storage_context,
verbose=True,
)
query_engine = RetrieverQueryEngine.from_args(
graph_rag_retriever,
)
which upon querying:
from IPython.display import display, Markdown
response = query_engine.query(
"Tell me about Peter Quill?",
)
display(Markdown(f"<b>{response}</b>"))
gives an output like:
Entities processed: ['Star', 'Lord', 'Marvel', 'Quill', 'Galaxy', 'Guardians', 'Guardians of the Galaxy', 'Star-Lord', 'Peter Quill', 'Peter']
Entities processed: ['Star', 'Lord', 'Marvel', 'Quill', 'Galaxy', 'Guardians', 'Guardians of the Galaxy', 'Star-Lord', 'Peter Quill', 'Peter']
Graph RAG context:
The following are knowledge sequence in max depth 2 in the form of `subject predicate, object, predicate_next_hop, object_next_hop ...` extracted based on key entities as subject:
Guardians, is member of, Guardians, was experimented on, by the High Evolutionary
Guardians, is member of, Guardians, considered to tell, origins
Guardians, is member of, Guardians, origins, team-up movie
Guardians, is member of, Guardians, befriended, his fellow Batch 89 test subjects
Guardians, is member of, Guardians, sought to enhance and anthropomorphize animal lifeforms, to create an ideal society
Guardians, is member of, Guardians, is creator of, Rocket
Guardians, is member of, Guardians, is, Mantis
Guardians, is member of, Guardians, is half-sister of, Mantis
Guardians, is member of, Guardians, is, Kraglin
Guardians, is member of, Guardians, developed psionic abilities, after being abandoned in outer space
Guardians, is member of, Guardians, would portray, Cosmo
Guardians, is member of, Guardians, recalls, his past
Guardians, is member of, Guardians
Guardians, is member of, Guardians, focus on, third Guardians-centric film
Guardians, is member of, Guardians, is, Rocket
Guardians, is member of, Guardians, backstory, flashbacks
Guardians, is member of, Guardians, is former second-in-command of, Ravagers
Quill, is half-sister of, Mantis, is member of, Guardians
Quill, is half-sister of, Mantis, is, Mantis
Quill, is in a state of depression, following the appearance of a variant of his dead lover Gamora
Quill, is half-sister of, Mantis
Peter Quill, is leader of, Guardians of the Galaxy, is sequel to, Guardians of the Galaxy
Peter Quill, was raised by, a group of alien thieves and smugglers
Peter Quill, would return to the MCU, May 2021
Peter Quill, is leader of, Guardians of the Galaxy
Peter Quill, is half-human, half-Celestial
Peter Quill, was abducted from Earth, as a child
Guardians of the Galaxy, is sequel to, Guardians of the Galaxy, released in, Dolby Cinema
Guardians of the Galaxy, is sequel to, Guardians of the Galaxy, released on, Disney+
Guardians of the Galaxy, is sequel to, Guardians of the Galaxy, is sequel to, Guardians of the Galaxy Vol. 2
Peter Quill is the leader of the Guardians of the Galaxy and the main protagonist of the Guardians of the Galaxy films. He was raised by a group of alien thieves and smugglers, and was abducted from Earth as a child. He is half-human, half-Celestial, and has the ability to wield an energy weapon called the Infinity Stone. He is set to return to the MCU in May 2021.
Colab notebooks that can be referred to, for diving deeper into the implementation: GraphRAG implementation with LlamaIndex and Knowledge GraphRAG Query Engine.
Benchmark evaluations reveal that while traditional RAG methods perform well on straightforward datasets, GraphRAG excels in handling queries that demand multihop reasoning. Empirical comparisons show that GraphRAG delivers notable performance improvements, particularly with larger models, by efficiently bridging gaps that standard RAG often leaves unaddressed. In production, LinkedIn’s customer service team experienced a 28.6% reduction in median resolution time per issue after incorporating GraphRAG into their AI strategies, demonstrating its significant operational impact. Moreover, the modular design of GraphRAG supports the development of supplementary tools—such as hallucination detection and prompt adherence models—which further enhance LLM reliability by pinpointing inaccuracies and ensuring that generated responses adhere to the intended context. These challenges have also been a focus in discussions from the AIMon fireside webinar.
The integration of graph structures into retrieval augmented generation opens up new avenues for research and development. Future work is likely to focus on refining hybrid models that seamlessly combine graph-based and vector-based retrieval methods. Additionally, efforts to reduce error propagation in the multistage GraphRAG pipeline will be essential for broadening its application across different domains and languages. Advancements in this area promise to further bridge the gap between structured knowledge and LLM applications, potentially leading to more accurate, robust, and context-aware AI systems.
GraphRAG represents a significant leap forward in the evolution of LLM applications. By merging the structured richness of knowledge graphs with the broad capabilities of vector-based retrieval, GraphRAG enables a more detailed and context-aware response mechanism. The insights drawn from both the AIMon fireside webinar and contemporary research highlight its potential to transform how we approach complex information retrieval challenges. As GraphRAG continues to evolve, its hybrid architecture and modular design will likely serve as a foundation for the next generation of intelligent, context-driven LLM applications.
AIMon helps you build more deterministic Generative AI Apps. It offers specialized tools for monitoring and improving the quality of outputs from large language models (LLMs). Leveraging proprietary technology, AIMon identifies and helps mitigate issues like hallucinations, instruction deviation, and RAG retrieval problems. These tools are accessible through APIs and SDKs, enabling offline analysis real-time monitoring of LLM quality issues.