
Thu Dec 05 / Puneet Anand
RAG is a technique that enhances the generation of an output from a Large Language Model (LLM) by supplementing the input to the LLM with relevant external information. In this article, we will cover the different components and types of RAG systems.
Large Language Models (LLMs) have revolutionized how businesses interact with data, customers, and internal operations. Built on advanced deep learning architectures like the Transformer, LLMs are designed to process and generate human-like text by understanding the nuances of language. Models such as OpenAI’s GPT, Google’s PaLM, and others have showcased unprecedented capabilities in tasks ranging from natural language understanding to content generation, code writing, and even reasoning.
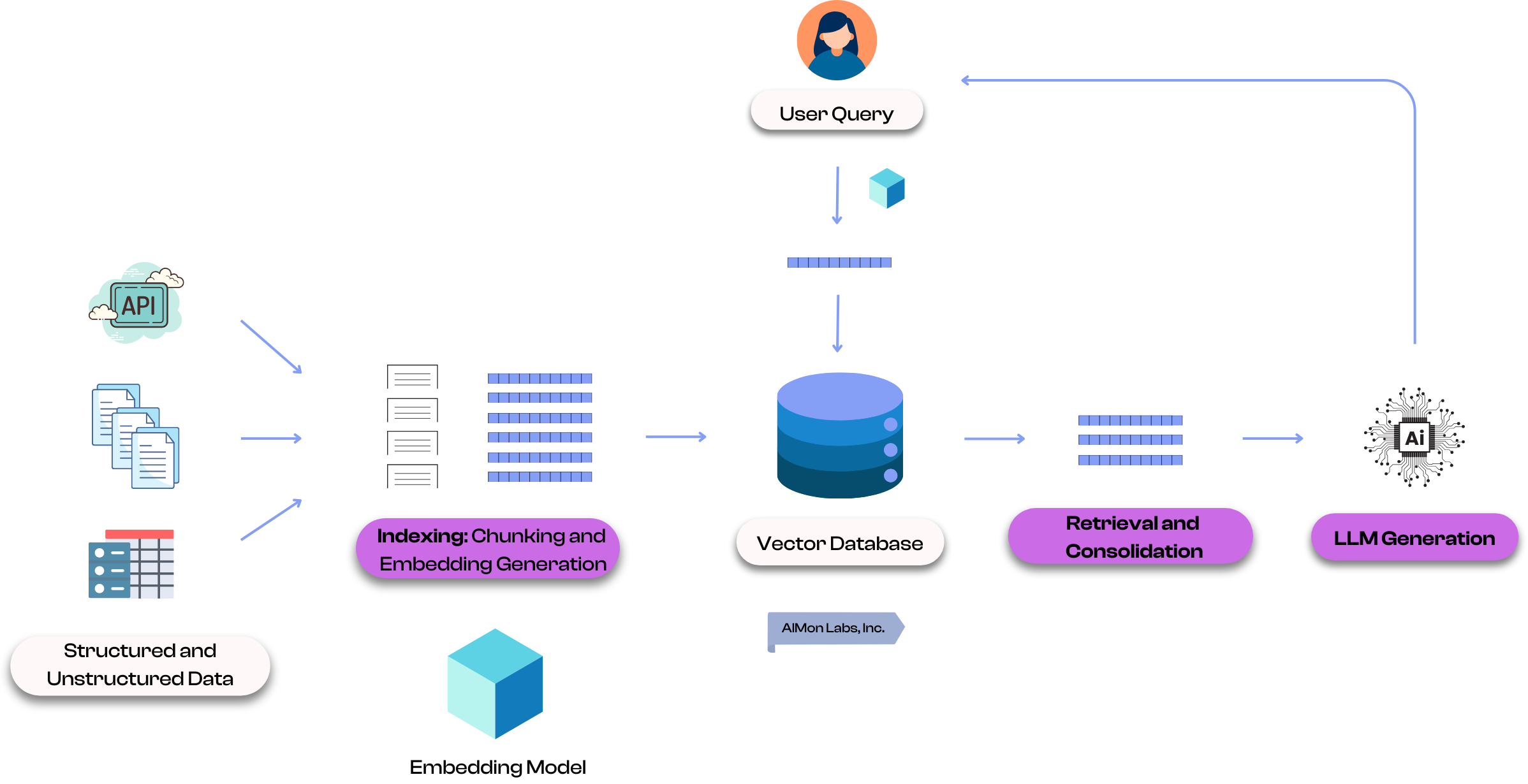
Retrieval-Augmented Generation (RAG) is a technique that enhances the generation of an output from a Large Language Model (LLM) by supplementing the input to the LLM with relevant external information. Instead of relying solely on the internal knowledge the LLM was trained with i.e. the knowledge encoded in the model’s parameters, a RAG system retrieves relevant information from external data sources (e.g., tickets, database tables or collections, internal company documents) and uses this information as additional context for the LLM to generate more accurate and relevant responses.
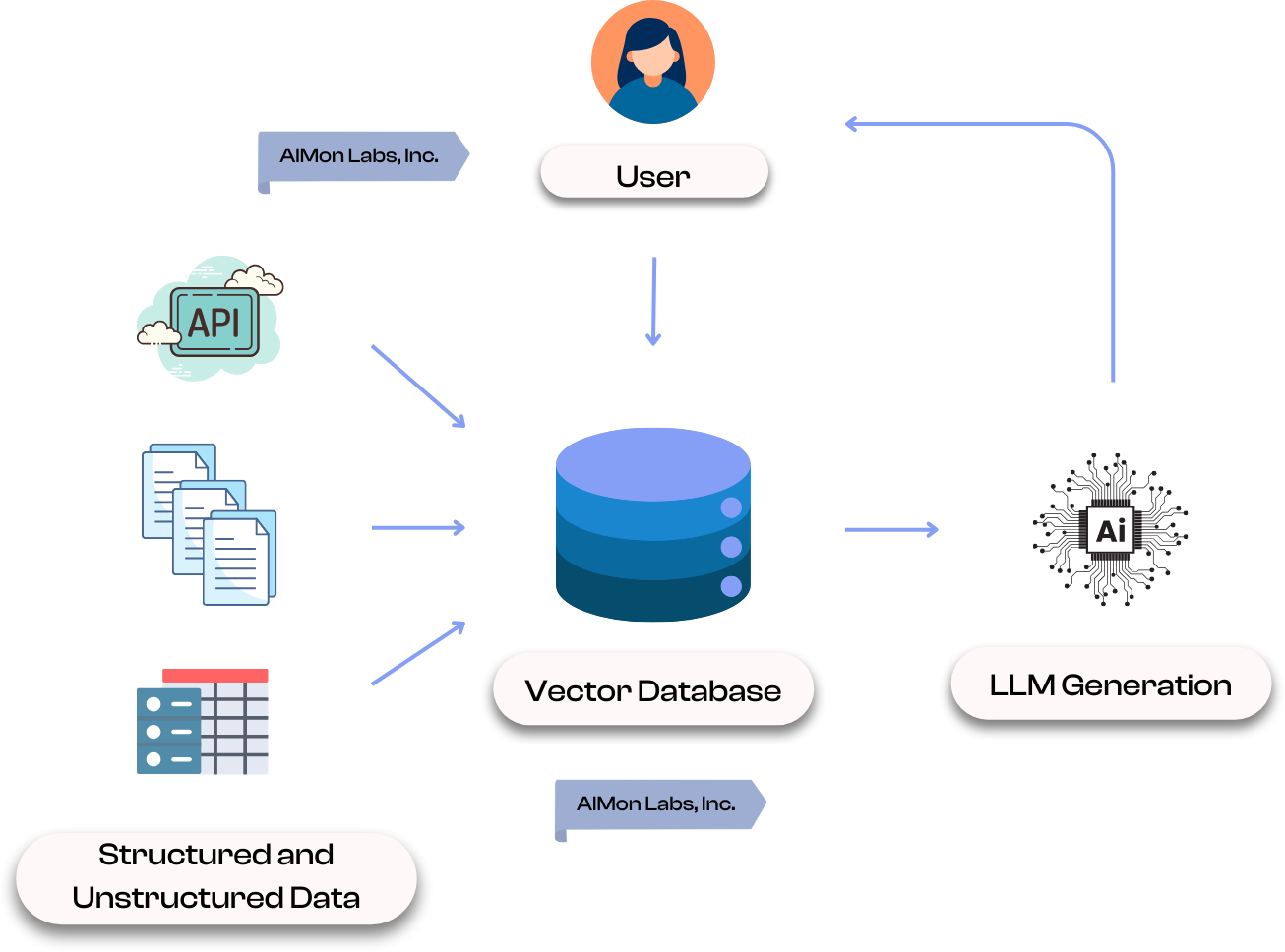
RAG works similar to traditional semantic or neural search systems. The steps below correlate with the enumerated steps in the diagram.
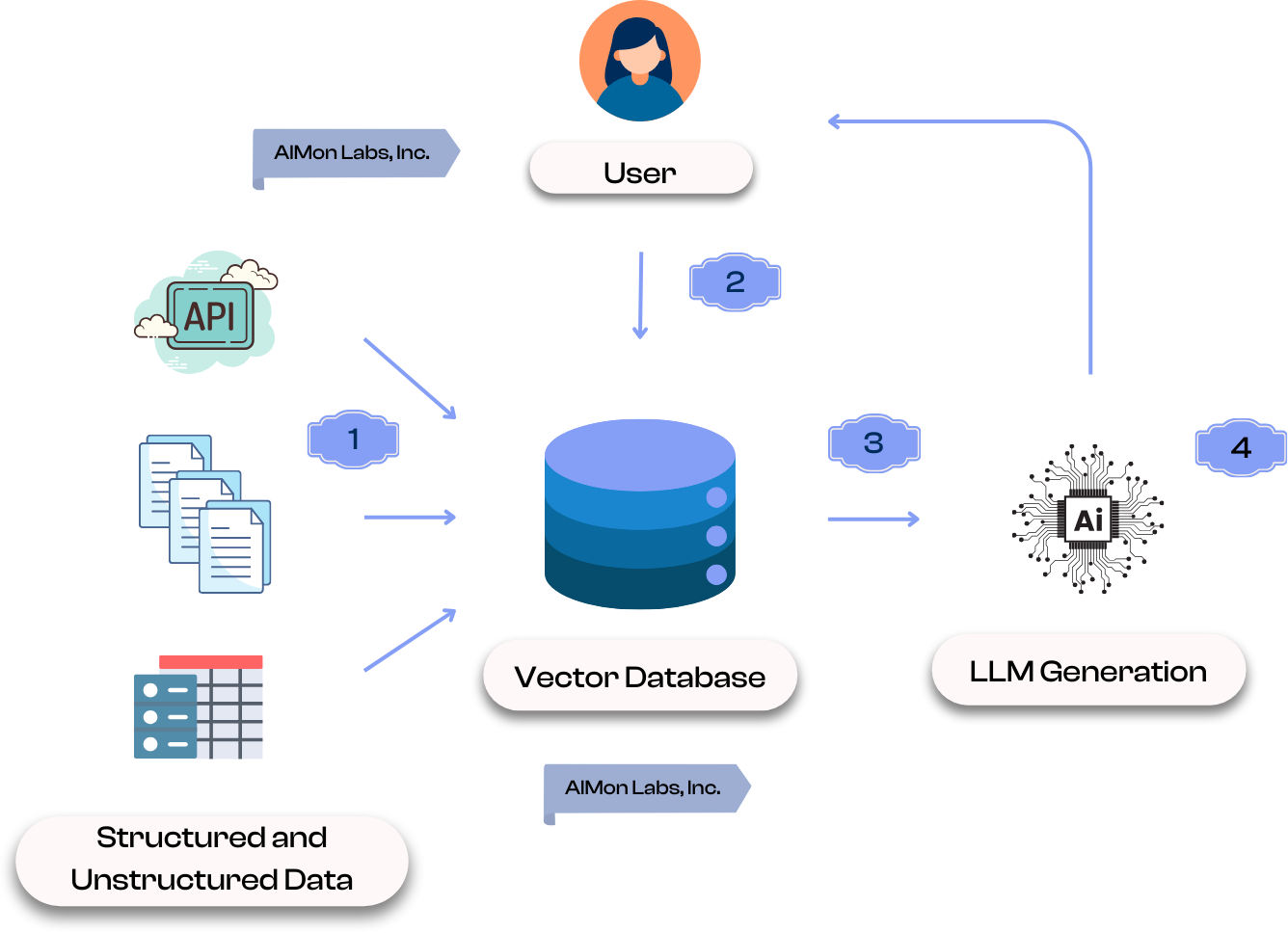
The choice of vector databases used is important. Click here to read our comparison of various vector databases.
LLMs, while powerful, have limitations when deployed in an enterprise context. Since they are trained on static datasets and cannot update their knowledge after training (unless techniques like fine-tuning are employed), they may hallucinate or generate incorrect information, especially for domain-specific or queries that require knowledge of data specific to a user, company, or industry.
RAG addresses these issues by grounding the model’s output in up-to-date, domain-specific information retrieved from relevant sources, making it particularly valuable for a variety of enterprise use cases, for example, Customer Support where tickets and knowledge articles are in a constant state of flux. To summarize the key benefits of using RAG:
A RAG system consists of three main components: Indexing, Retrieval, and Generation. Each plays a critical role in ensuring the system delivers accurate, contextually rich responses. Indexing prepares a searchable knowledge database, Retrieval fetches relevant data in real time, and Generation synthesizes a response using the retrieved information.
Indexing is the foundational step in a Retrieval-Augmented Generation (RAG) system, where raw data, structured or unstructured, is processed and stored for efficient retrieval. This involves converting data (text, structured, etc.) into vector embeddings using ML models called Embedding Models that capture semantic meanings behind that data. These embeddings can be stored in a vector database, allowing for fast similarity searches. Indexing ensures that the system can quickly locate and retrieve relevant information based on user queries, forming the backbone of a robust and responsive RAG system.
Embedding models are ML models designed to convert data into dense vector representations. These vectors capture the semantic meaning of user queries or data that is being indexed, enabling comparisons and similarity searches based on their semantic proximity. Embedding models are a core part of RAG applications. They are used in both the indexing of data and the retrieval of information when new queries are issued. Open AI text-embedding-3-small and NVidia NV-embed-v2 are two of the popular embedding models in the industry.
Retrieval is a critical component of a RAG system, responsible for identifying and fetching the most relevant information to answer a user’s query. When a user submits a query in natural language, it is transformed into a vector embedding that captures its semantic meaning. The system then searches the vector database using similarity metrics like cosine similarity or Euclidean distance to locate data that closely matches the query. This process ensures that only the most contextually relevant information is retrieved, which can then be combined with the query to provide enriched input to the LLM. Effective retrieval is key to ensuring the final response is accurate, contextually rich, and aligned with the user’s query.
This stage involves multiple steps, including filtering irrelevant or redundant information to minimize noise and contradictions. Documents are often re-ranked based on their semantic relevance, metadata, or contextual fit to ensure the most valuable pieces of information are prioritized. Consolidation may also include summarization or chunk reduction strategies to address token limits inherent to LLMs, ensuring that only the most pertinent data is passed on. Advanced techniques, such as weighting certain document attributes or dynamically adjusting the number of included chunks, are also employed to optimize the context. In the retrieval phase, the goal is to get the most promising candidate chunks that might answer a user query. In the consolidation phase, the goal is to narrow the retrieved chunks down to a highly precise set that could be used by the LLM to answer the user query
Once the relevant data is retrieved, it is passed to an LLM (like GPT-4o) as part of the input context. The LLM uses this retrieved context to generate outputs that are informed by the relevant company, domain, industry or use-case specific knowledge.
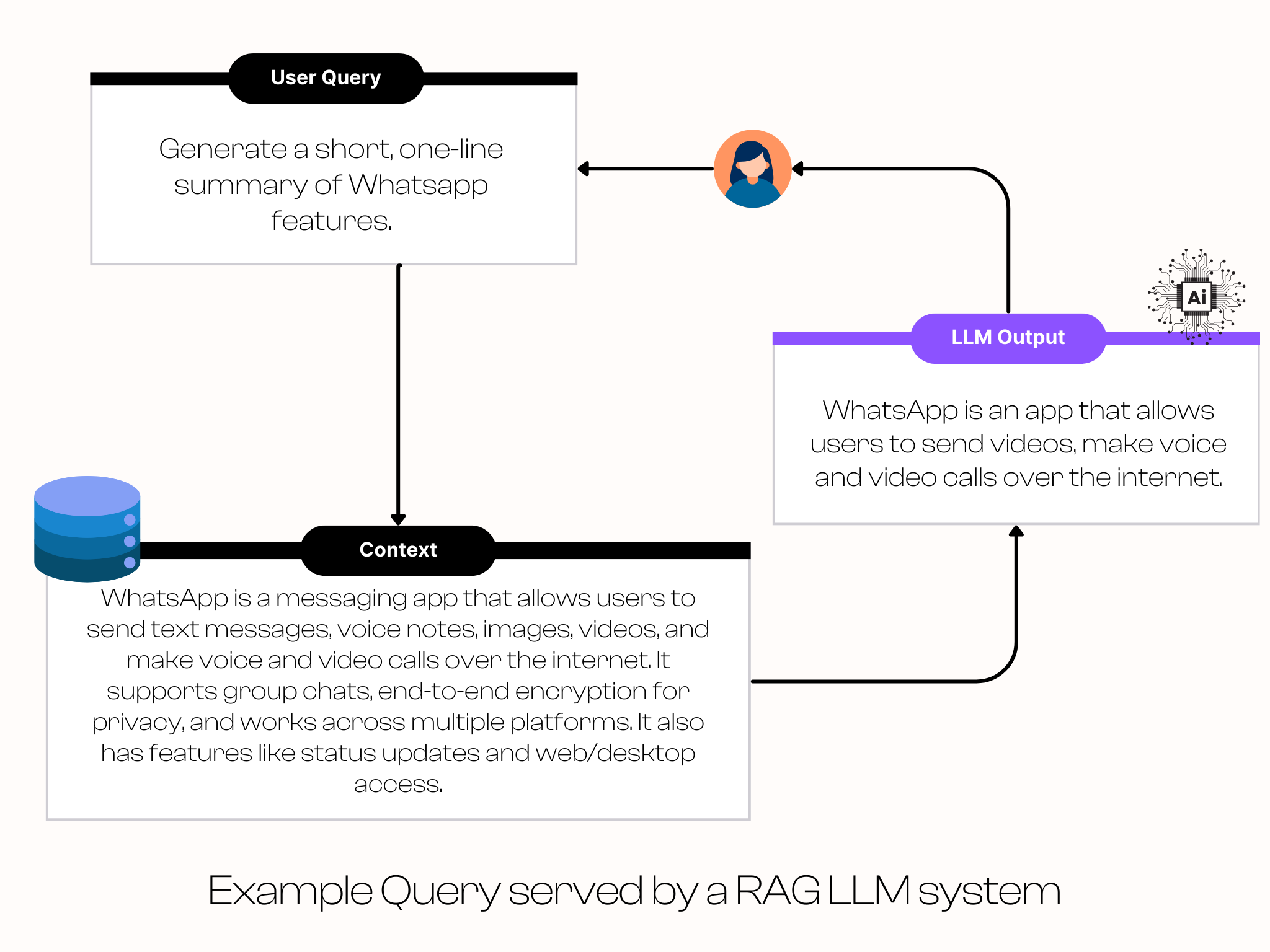
Here is a quick example of a user requesting a response from the RAG-based LLM application. The relevant context is pulled from the database for the provided query and passed to the LLM for generation of an appropriate contextual response.
RAG systems can be categorized based on their underlying architecture and the techniques used to retrieve and process information. Here are some prominent types:
This type of RAG leverages keyword-based search or semantic search techniques to retrieve relevant documents from a knowledge base. It might also employ advanced language models like BERT or RoBERTa to understand the query’s intent and context, enabling more precise document retrieval.
This type system constructs a knowledge graph representing entities, relationships, and their attributes, allowing for efficient navigation and reasoning over the information.
Hybrid RAG combines Text and Graph. It leverages both text-based and graph-based techniques to enhance retrieval and reasoning capabilities. A Multi-Modal RAG may incorporate multimodal data (text, images, videos) to provide richer and more comprehensive responses.
The choice of RAG system depends on various factors, including data complexity, query complexity, real-time requirements, and explainability. For simple, text-based knowledge bases, text-based RAG may suffice. However, for complex, interconnected data, graph-based RAG can provide more accurate and nuanced responses. Advanced queries that require a deep understanding of context and relationships benefit from graph-based RAG. While text-based RAG is generally faster, graph-based RAG can be more computationally intensive, especially for large knowledge graphs. Additionally, graph-based RAG can offer more transparent explanations for its responses by tracing the reasoning steps through the knowledge graph. By carefully considering these factors, organizations can select the most suitable RAG system to meet their specific needs and achieve optimal performance.
In this article, we covered how RAG enhances LLMs by combining external, up-to-date information with their generative capabilities, diving into its key components: indexing, retrieval, and generation. Additionally, we discussed the role of embedding models and the practical applications of RAG in enterprise settings. By grounding responses in relevant, domain-specific data, RAG addresses LLM limitations, making it an invaluable tool for accurate, context-aware decision-making in dynamic environments.
Next up, we will go over what are the top problems developers face with implementing RAG systems successfully.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.