

/ 2024
By: Bibek Paudel, Alex Lyzhov, Preetam Joshi, Puneet Anand
After extensive research and development, we are excited to announce the launch of HDM-1, our cutting-edge Hallucination Detection model, that outperforms all competitors.
HDM-1 delivers unmatched accuracy and real-time evaluations, setting a new standard for reliability in hallucination evaluations for open-book LLM applications.

LLM hallucination occurs when an LLM generates statements that contradict or deviate from the facts provided in its context. This can result in factual inaccuracies or the creation of entirely fabricated information, which undermines trust in AI outputs and leads to significant errors in applications where accuracy is critical.
To address this problem, developers often rely on context augmentation backed by internal or external knowledge sources (RAG). However, LLMs may still generate inaccurate content, exposing LLM app builders to significant risks like reputational damage or negative financial impact.
HDM-1 is the ultimate solution for tackling the problem of LLM hallucinations, bringing both precision and accuracy to ensure AI outputs are factual and reliable.
AIMon HDM-1 is our proprietary hallucination detection model, based on cutting-edge research and internally curated datasets.
It is immediately available in two different sizes:
Both models are smaller-sized single models specialized to detect inaccuracies and fabrications for real-time and offline evaluation use cases. They can be customized and deployed in your trusted network (on-premise) or hosted by AIMon.
The performance of both models has been rigorously tested across a range of industry-standard hallucination datasets. Below, we outline key performance metrics and how HDM-1 models compare to similar solutions. For all these measures, a higher number means better performance, with 100 being the highest possible score and 0 being the lowest.
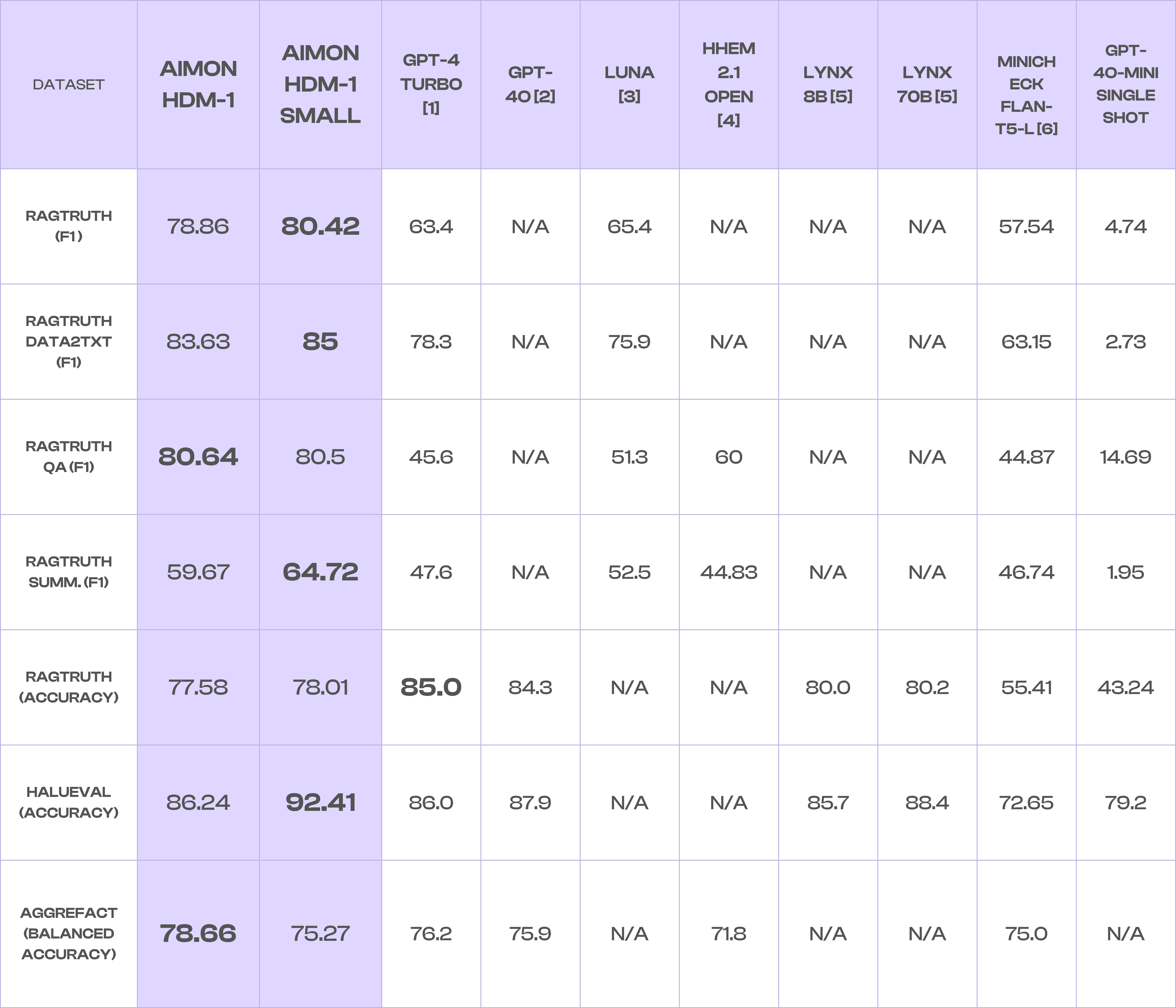
Table 1: F1 Score, Accuracy, and Balance Accuracy metrics for Hallucination evaluation models on various benchmark datasets.
N/A = Not available, not reported at source, or could not compute.
Notes:
Precision is a valuable metric for reporting on hallucinations because it measures the proportion of correctly detected hallucinations (true positive predictions) out of all detected hallucinations (true and false positive predictions), helping identify how many of the flagged results are genuinely inaccurate. Precision is more important than recall since false positives tend to result in a poor user experience due to the noise added by them. F1 Score combines both Precision and Recall into a measure that balances them. We also include the Balanced Accuracy (Bal.Acc.) measure for the LLM-AggreFact benchmark, as this is the measure used in the LLM-AggreFact leaderboard [2]. Balanced Accuracy measures the average accuracy of a model for both the minority and majority classes and is useful when dealing with imbalanced data, where one class has more labels than another.
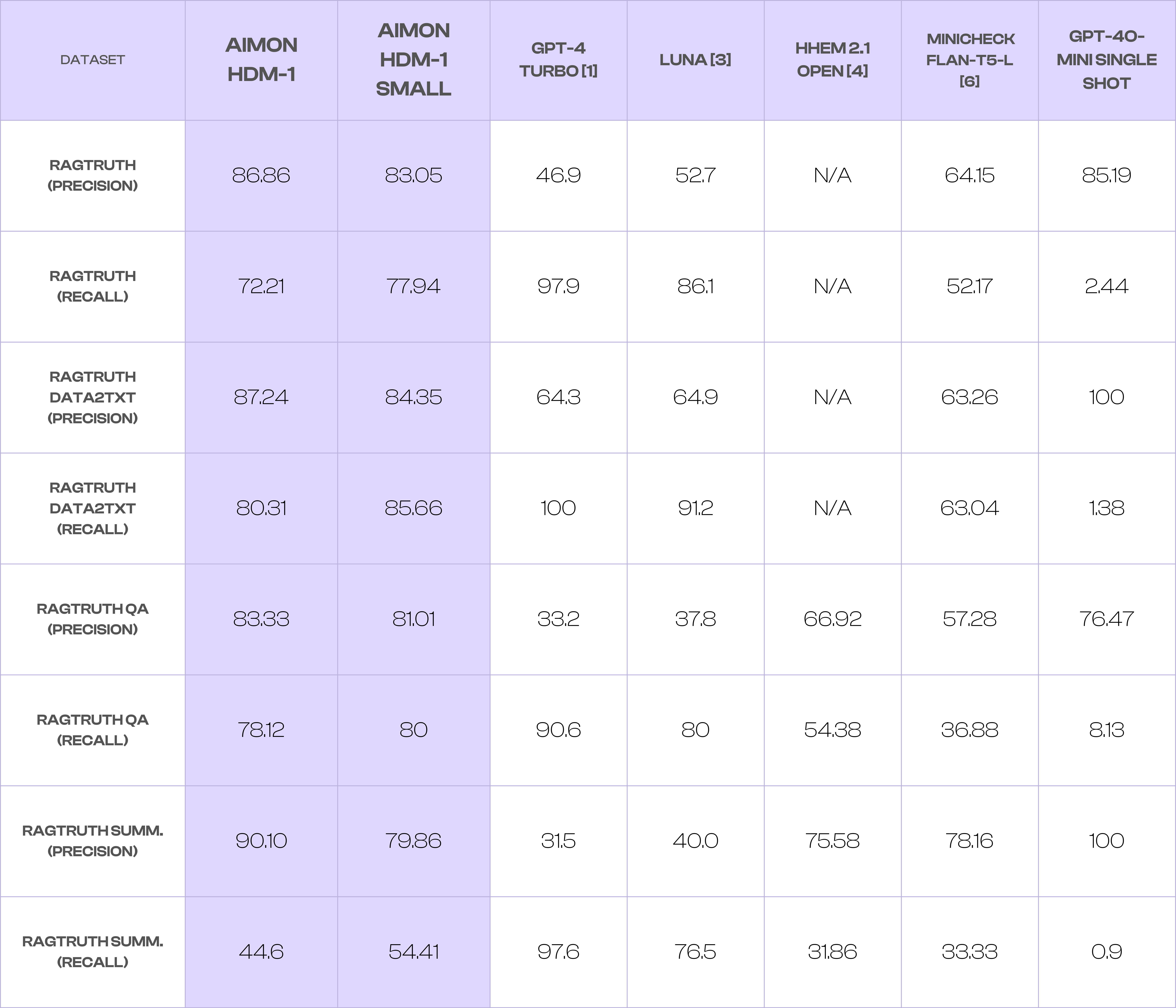
Table 2: Precision and Recall metrics for Hallucination Evaluation models on the RAGTruth datasets.
Notes:
A key lesson we learned from our customers is that the mainstream operationalization of LLMs requires real-time evaluations and mitigation strategies. That is why latency was top of mind as we architected and optimized HDM-1 from the get-go.
A low response time opens up opportunities such as re-prompting and multi-sampling for our LLM App builders. Needless to say, performance efficiency varies with the input size and hardware configurations used, meaning that HDM-1 can be significantly faster when a cluster of GPUs is deployed.
L4 and A100 are both part of NVIDIA’s lineup designed for AI workloads.
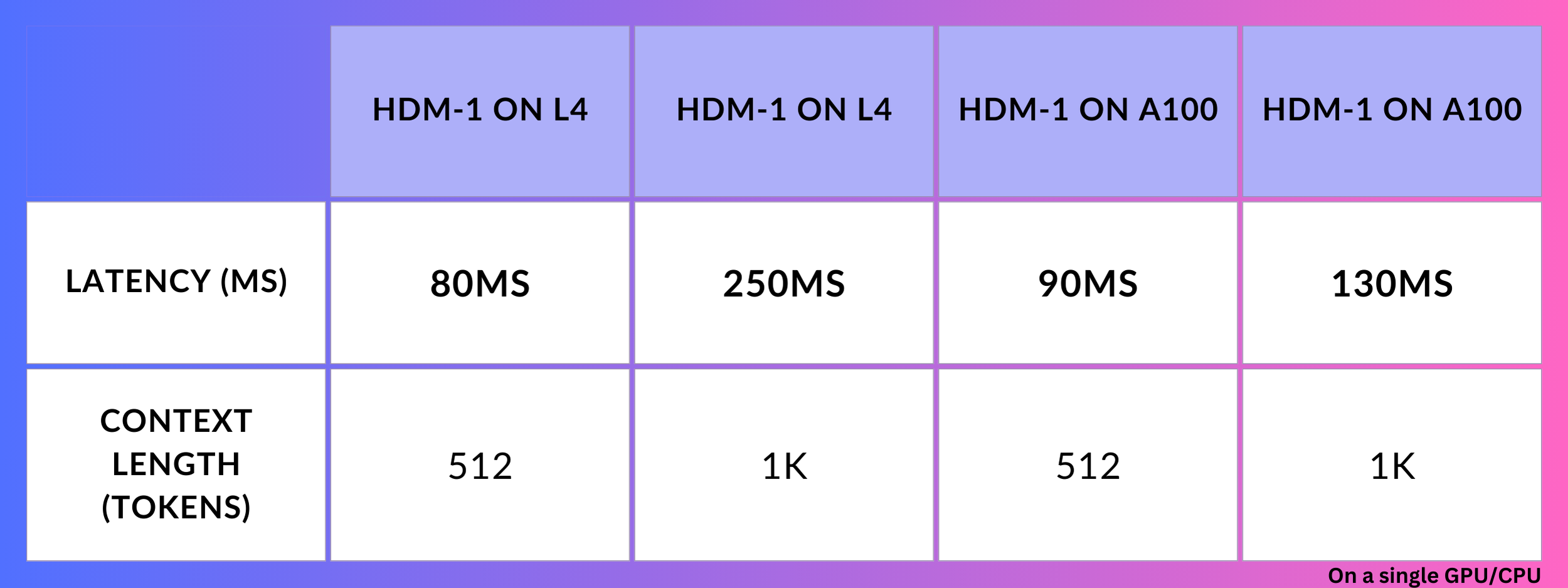
Latency metrics computed on just a single GPU.
Additionally, the smaller version, HDM-1 Small can be run on CPUs. On a single AMD EPYC 7R13, the smaller model performs at a respectable 1-2.5 seconds for 500-1000 tokens.
Here is the detailed latency metrics for HDM-1 Small:
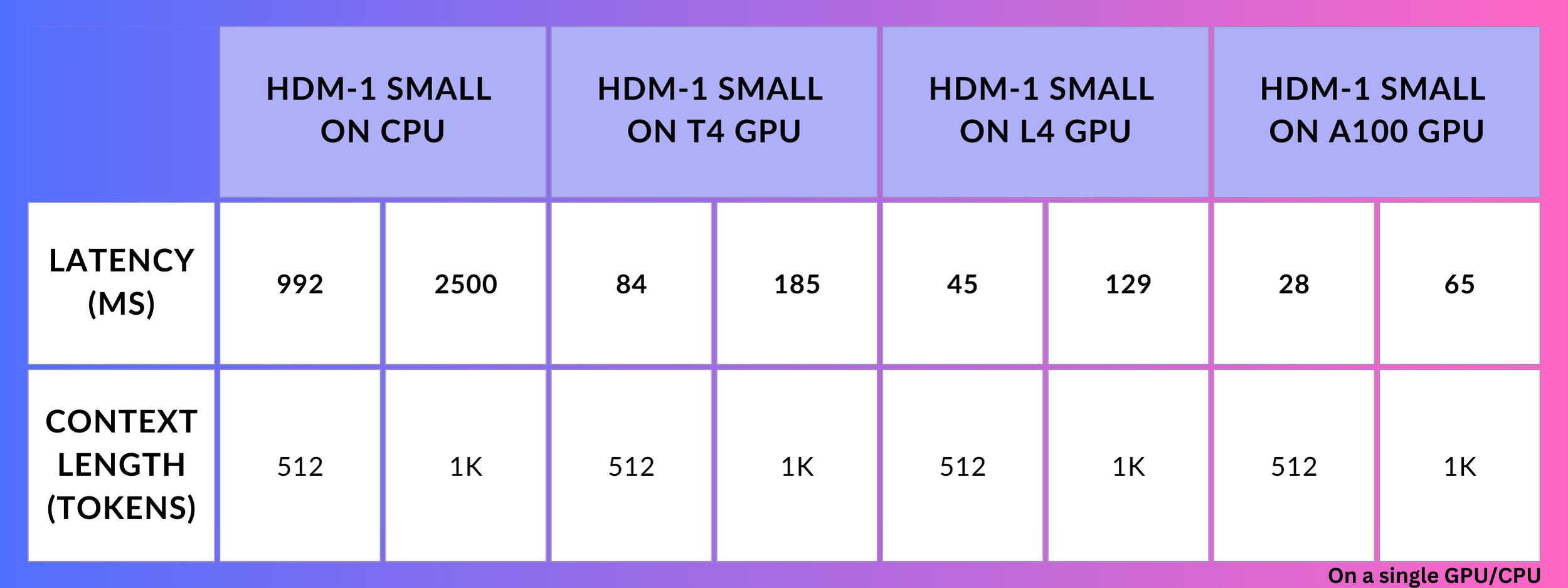 Latency metrics computed on just a single CPU or GPU.
Latency metrics computed on just a single CPU or GPU.
Notes:
To demonstrate how HDM-1 works for a simple hallucination, we picked a context about Meta’s Whatsapp, a summarization query, and an LLM output. We then tested AIMon’s HDM-1 (available for testing through our sandbox) and GPT-4o with this example to check if they appropriately identify it. Please note that the LLM output does not have a hallucination and this example is not in the training data for HDM-1.
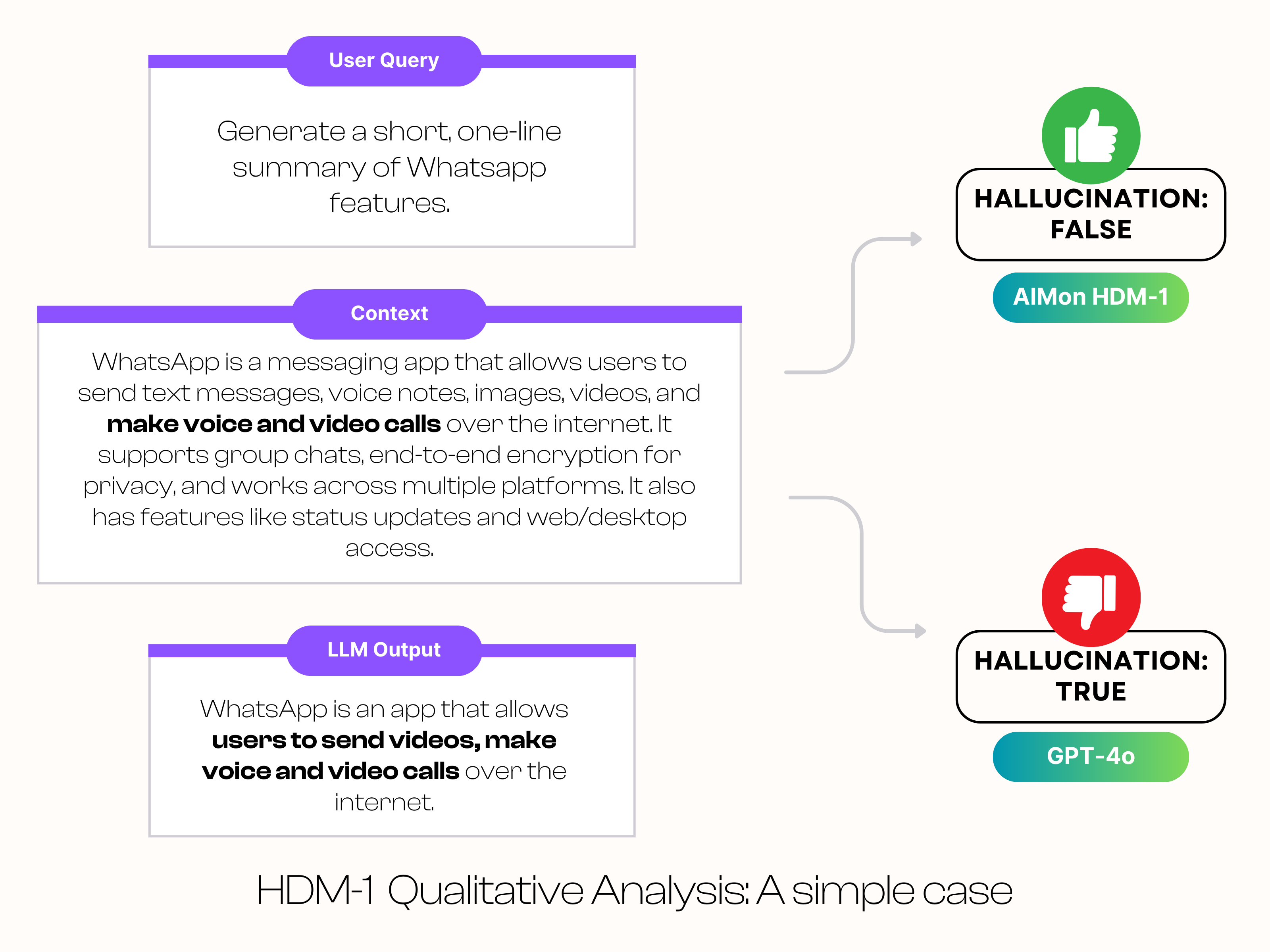
In this case, GPT-4o fails to identify the LLM output as accurate, whereas HDM-1 correctly labels it as a hallucination.
In the next example, we will look at a more complicated hallucination case about “Moonbabies”, a Swedish bubblegum pop duo formed in 1997.
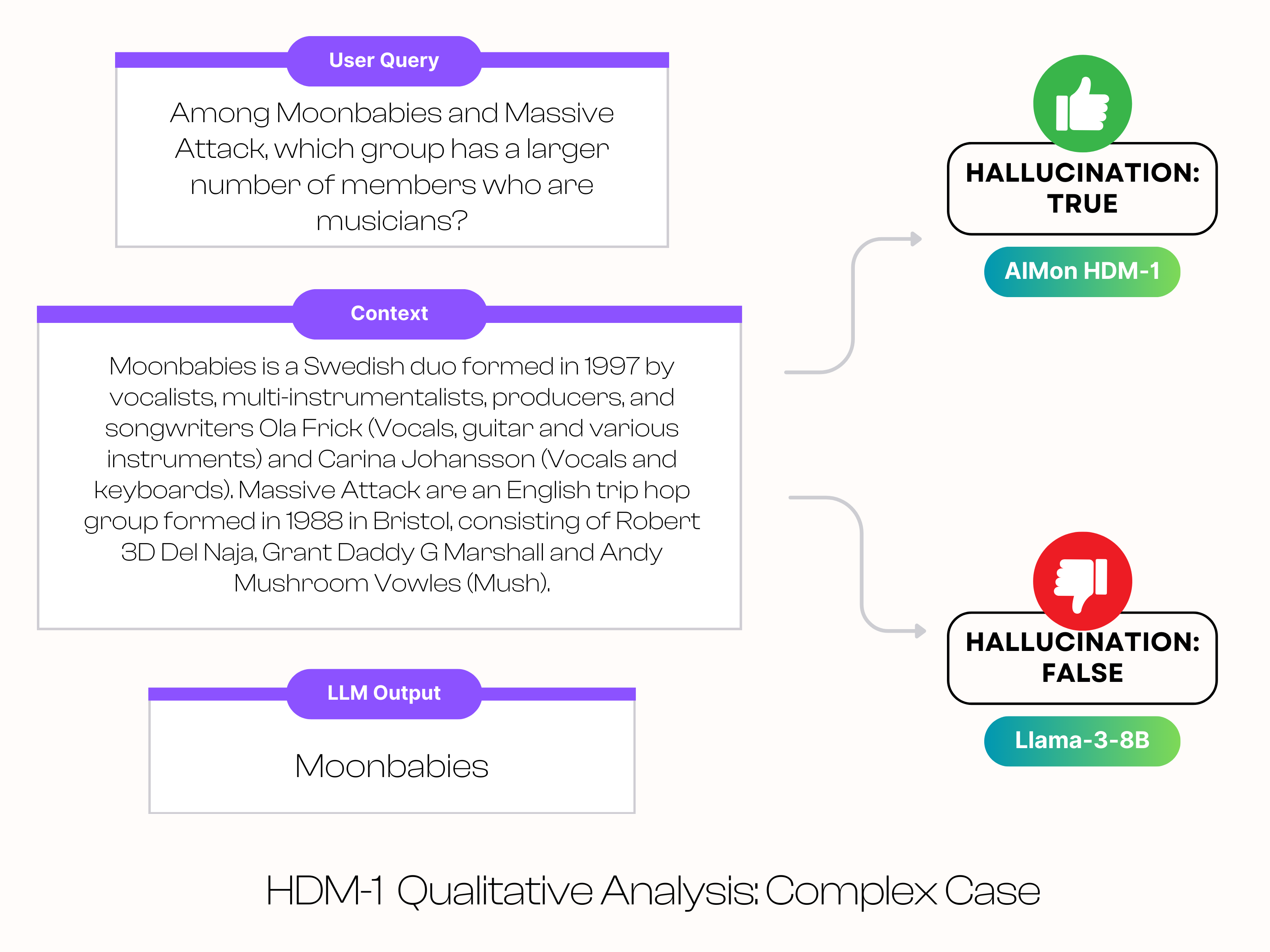
As mentioned above in the context box, the band “Massive Attack” has 3 musicians and “Moonbabies” has 2 musicians. Llama-3-8B decides that Moonbabies is the music group with more members but AIMon correctly HDM-1 identifies it as a hallucination.
Even for this complicated problem pertaining to counting, HDM-1 was able to correctly classify that Moonbabies is the incorrect answer as it has fewer members.
Would you like to try this example out on our sandbox with “Massive Attack” as the LLM Output and see what HDM-1 identifies it as?
This is our small first step in catching inaccuracies for more complex tasks such as counting, addition, subtraction, and many other complicated problems.
These examples demonstrate AIMon’s superior hallucination detection capabilities compared to much larger LLMs such as Llama 3 8B and GPT-4o, which is thought to be greater than 1 Trillion parameters in size. On the other hand, HDM-1 models are sub-500 million parameter models yet provide SOTA hallucination detection capabilities.
HDM-1 and HDM-1 Small are available through our Unified API on the AIMon platform with all other detectors, such as Instruction Adherence and Context Quality included. We offer 1M free tokens to allow you to run your evaluations. Once the first million tokens are exhausted, the pricing is currently set at $0.49 per Million tokens.
LLMs are a common choice for conducting evaluations. As you think about comparing AIMon to LLM evaluators, consider a few important points:
“The productivity gains provided by LLMs are only as valuable as the trust in the LLMs’ output. Reliability tools like AIMon are key to enabling that business value,” said Mosi K. Platt, Senior Security Compliance Engineer. “That is critical to professionals in fields like security compliance where programs are looking to drive adoption of these tools and use them as force multipliers.”
“We recently moved from a popular OSS framework to AIMon for its accuracy and latency benefits,” said Joel Ritossa, CTO of a YCombinator-backed startup, Duckie.
“AIMon will enable us to boost accuracy in GenAI solutions for SAP Clean Core to achieve superior quality analysis and automation in custom code transformations,” said Vyom Gupta, President and COO of smartShift.
If you are interested in on-premise deployments, HDM-1 is available on the AWS Marketplace. Please reach out to us for more details. For other situations, you can try AIMon without signing up using our sandbox and if you like our powerful detectors, you can also sign up for free to use the AIMon platform and answer questions like:
With quick one-line additions (using our decorators), it is a breeze to instrument your LLM apps with our Python and TypeScript SDKs. You can quickly configure the tool to track select key metrics such as hallucination (using HDM-1), instruction adherence, and context quality.
You can get started with AIMon by checking out the quick start page on our docs and reviewing the available recipes and examples.
https://www.app.aimon.ai/?screen=signup
https://aimon.ai/posts/llm-as-judge-pros-and-cons
Open-book and closed-book LLM apps differ on whether the apps can use external resources to answer queries. In an open-book setting, the apps can use external resources, whereas in a closed-book setting, the apps cannot access external resources. RAG (Retrieval Augmented Generation), a popular choice for enterprise LLM app design, is an example of open-book setting, since it includes retrieved information in the prompt.
Precision measures how accurate your positive predictions (hallucinations) are. It answers the question: When the model predicts something as a hallucination, how often is it correct?
Recall measures how well the model finds all actual positives (hallucinations). It answers the question: Of all the actual hallucinations, how many did the model correctly identify?
F1 score is a harmonic mean of both precision and recall. It gives a higher score only if both Precision and Recall are high.
Accuracy measures the overall correctness of the model. It answers the question: How much was the model correct overall?